![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Principi di base della rete InternetUna delle ragioni principali del successo di Internet risiede senza dubbio nell'efficienza, semplicità di uso e convenienza delle sue basi tecnologiche. Abbiamo visto cosa sia una rete di computer in generale e quali siano le sue strutture o, per dirla con la terminologia informatica, il suo hardware, soffermandoci in particolare sulla struttura della rete Internet. Ma, come è noto, nel mondo dell'informatica un ruolo altrettanto importante è svolto dal livello logico, il software. In questo capitolo, dunque, ci soffermeremo proprio su questo livello logico della rete, e getteremo, anche da questo punto di vista, un'occhiata 'dentro la scatola'. Non intendiamo certo fornire tutte le nozioni che troverebbero posto in un manuale tecnico sui sistemi di internetworking: cercheremo solamente di introdurre i principi fondamentali delle tecnologie che garantiscono a Internet di funzionare in modo efficiente e sicuro. Questa introduzione, se per un verso risponde alle esigenze di completezza cui un manuale deve ottemperare, fornisce nondimeno al lettore alcune nozioni che dovrebbero far parte del bagaglio di conoscenze di un utente 'esperto' della rete Internet. Un bagaglio indispensabile per sfruttarne al meglio le potenzialità: sapere come funzionano le cose, infatti, permette di individuare le cause di eventuali problemi o malfunzionamenti, e, se non sempre di risolverli, almeno di dare informazioni precise a chi dovrà intervenire. Inevitabilmente, saremo costretti ad usare un certo numero di strane sigle, con le quali vengono di norma designate le tecnologie della rete. Ma a questo probabilmente i nostri lettori avranno già fatto l'abitudine: d'altra parte il lessico di Internet è popolato di sigle e il navigatore esperto deve rassegnarsi a conviverci. In ogni caso, la lettura di questo capitolo, come di tutti gli altri in questa sezione, non è indispensabile per utilizzare con buon successo i vari servizi che abbiamo già studiato nella prima parte del manuale. Volendo potrete perciò saltarlo, e magari tornarci quando avrete maggiore dimestichezza con il mondo di Internet. Un linguaggio comune: il protocollo TCP-IPInternet è uno strumento di comunicazione. Uno strumento di comunicazione tra i computer, e tra gli uomini che usano i computer interconnessi attraverso la rete. Naturalmente i due soggetti in campo, computer e uomini, hanno esigenze diverse, spesso contrastanti, che occorre tenere presenti per fare in modo che la comunicazione vada a buon fine. Le tecnologie su cui si basa Internet si sono evolute nel corso degli anni proprio per rispondere con la massima efficienza a queste esigenze. Il primo problema in ogni processo di comunicazione è naturalmente la definizione di un linguaggio che sia condiviso tra i diversi attori che comunicano; attori che, nel caso di Internet, sono in primo luogo i computer. E i computer, come ben si sa, pur usando tutti lo stesso alfabeto - il codice binario - 'parlano' spesso linguaggi differenti e incompatibili. Fuori di metafora, computer diversi usano sistemi operativi, codici di caratteri, strutture di dati, che possono essere anche molto diversi. Per permettere la comunicazione tra l'uno e l'altro è necessario definire delle regole condivise da tutti. Questa funzione, nell'ambito della telematica, viene svolta dai protocolli. Nel mondo diplomatico per 'protocollo' si intende una serie di regole di comportamento e di etichetta rigidamente codificate, che permettono a persone provenienti da diversi universi culturali di interagire senza creare pericolose incomprensioni. Protocolli sono detti anche gli accordi o i trattati internazionali. Queste accezioni del termine possono essere accolte per metafora anche nell'ambito della telematica: un protocollo di comunicazione definisce le regole comuni che un computer deve conoscere per elaborare e inviare i bit attraverso un determinato mezzo di trasmissione fisica verso un altro computer. Un protocollo dunque deve specificare in che modo va codificato il segnale, in che modo far viaggiare i dati da un nodo all'altro, in che modo assicurarsi che la trasmissione sia andata a buon fine, e così via. Nel caso di Internet, che interconnette milioni di computer e di sottoreti, basati su ambienti operativi e architetture hardware diverse, tali protocolli debbono rispondere ad esigenze particolarmente complesse. E come abbiamo visto la storia stessa della rete è stata scandita dallo sviluppo dei suoi protocolli fondamentali. Il nucleo fondamentale, l'insieme di protocolli che permettono il funzionamento di questo complesso e proteico sistema di comunicazione telematico, viene comunemente indicato con la sigla TCP/IP, che è un acronimo per Transmission Control Protocol/Internet Protocol. Possiamo affermare che una delle ragioni del successo di Internet risiede proprio nelle caratteristiche del suo protocollo di comunicazione. In primo luogo il TCP/IP è indipendente dal modo in cui la rete è fisicamente realizzata: una rete TCP/IP può appoggiarsi indifferentemente su una rete locale Ethernet, su una linea telefonica, su un cavo in fibra ottica, su una rete di trasmissione satellitare... e così via. È anzi progettato esplicitamente per integrare facilmente diverse tecnologie hardware in un'unica struttura logica di comunicazione. In secondo luogo il TCP/IP è un protocollo di comunicazione che risolve in modo molto efficiente i problemi tecnici di una rete geografica eterogenea come è Internet:
E infine, ma non secondariamente, TCP/IP è un open standard, le cui specifiche sono liberamente utilizzabili da chiunque. Questo ha permesso il rapido diffondersi di implementazioni per ogni sistema operativo e piattaforma esistente, implementazioni spesso distribuite gratuitamente o integrate in modo nativo nel sistema stesso. Un protocollo a stratiCiò che viene comunemente indicato come TCP/IP, in realtà, è costituito da un vero e proprio insieme di protocolli di comunicazione, ognuno con un compito specifico, organizzati in maniera gerarchica [74]. In termini tecnici si dice che è un 'protocollo a livelli di servizi' (layers of services). Per la precisione TCP/IP si basa su un modello a quattro livelli:
Nell'architettura TCP/IP ogni livello è gestito da uno o più protocolli. Durante lo svolgimento di una transazione, alla sequenza dei vari livelli corrisponde una sequenza di operazioni necessarie per la trasmissione dei dati. In fase di invio i dati partono dal livello delle applicazioni, e passano in sequenza attraverso la pila di strati; ogni protocollo riceve i dati dal livello superiore, aggiunge le informazioni di gestione che gli competono in una intestazione (header), e poi passa il tutto al livello inferiore, fino al livello che invia il segnale lungo il canale. In fase di ricezione avviene naturalmente il processo inverso. I dati arrivati mediante il livello fisico e il livello di rete passano al livello di trasporto che legge l'intestazione a lui destinata, ricompone il messaggio, e poi passa il tutto al livello applicativo. Naturalmente nella realtà le cose sono molto più complicate, ma questa descrizione rende l'idea. TCP/IP, insomma, può essere visto come una sorta di servizio di recapito basato su un meccanismo a scatole cinesi: al momento della spedizione i dati sono 'avvolti' in una scatola (che riporterà all'esterno alcune indicazioni sul contenuto), questa scatola viene inserita in un'altra scatola (con all'esterno un altro tipo di indicazioni), e così via. Al momento della ricezione le scatole vengono 'aperte' una dopo l'altra, ricavando da ognuna le informazioni su di essa riportate. Ogni interazione tra due computer della rete è costituita dalla confezione e dall'invio di una serie di scatole. In realtà, come abbiamo detto, il gruppo di protocolli TCP/IP in senso stretto non si occupa della gestione diretta della infrastruttura hardware della rete. Esso, infatti, è indipendente da tale infrastruttura, e questa sua caratteristica ne ha facilitato la diffusione. Esistono dunque una serie di specifiche che descrivono in che modo ogni singola architettura fisica di rete possa interfacciarsi con il TCP/IP: ad esempio per la rete Ethernet, il tipo di rete locale più diffusa al mondo, ci sono l'Address Resolution Protocol (ARP) e lo Standard for the Transmission of IP Datagrams over Ethernet Networks. Le implementazioni software dei protocolli TCP/IP normalmente integrano queste tecnologie, e dunque permettono di creare reti Internet/Intranet su qualsiasi tipo di cavo. Lo scambio dei dati: ad ogni computer il suo indirizzoLa trasmissione dei dati e la gestione del traffico tra i vari computer in una rete TCP/IP sono governati dall'Internet Protocol (IP). Il protocollo IP ha il compito di impacchettare i dati in uscita e di inviarli, trovando la strada migliore per arrivare ad un particolare computer tra tutti quelli connessi alla rete. Le informazioni necessarie a questo fine sono inserite in una intestazione (header) IP che viene aggiunta ad ogni pacchetto di dati. La tecnica di inviare i dati suddivisi in pacchetti (detti anche datagrammi) recanti tutte le informazione sulla loro destinazione è una caratteristica delle reti di tipo TCP/IP, che sono dette reti a commutazione di pacchetto. In questo modo è possibile usare lo stesso tratto di cavo fisico per far passare molte comunicazioni diverse, sia che provengano da più persone che operano sullo stesso computer, sia che provengano da più computer collegati a quel tratto di rete. Mai nessuno occuperà un certo tratto di rete fisica per intero, come invece avviene nella comunicazione telefonica. Questa tecnica di trasmissione dei dati permette una grande efficienza nella gestione dei servizi di rete: infatti se per una qualche ragione una singola sessione di invio si interrompe, il computer emittente può iniziare un'altra transazione, per riprendere in seguito quella iniziale. E occorre ricordare che, per un computer, interruzione vuol dire pochi millesimi di secondo di inattività! Il secondo compito del protocollo IP è l'invio dei dati per la 'retta via'. Per fare in modo che la comunicazione tra gli host vada a buon fine è necessario che ogni singolo computer abbia un indirizzo univoco, che lo identifichi senza alcuna ambiguità, e che indichi la via per raggiungerlo tra i milioni di altri host della rete. A questo fine viene impiegato uno schema di indirizzamento dei computer collegati in rete, che si basa su un sistema di indirizzi numerici. Ogni computer su Internet, infatti, è dotato di un indirizzo numerico costituito da quattro byte, ovvero da quattro sequenze di 8 cifre binarie. Normalmente esso viene rappresentato in notazione decimale come una sequenza di quattro numeri da 0 a 255 (tutti valori decimali rappresentabili con 8 bit), separati da un punto; ad esempio: 151.100.20.17 Questi indirizzi numerici hanno una struttura ben definita. Come abbiamo detto Internet è una rete che collega diverse sottoreti. Lo schema di indirizzamento rispecchia questa caratteristica: in generale la parte sinistra dell'indirizzo indica una certa sottorete nell'ambito di Internet, e la parte destra indica il singolo host di quella sottorete. La esatta distribuzione dei quattro byte tra indirizzo di rete e indirizzo di host dipende dalla 'classe' della rete. Esistono cinque classi di rete designate con le lettere latine A, B, C, D, E; di queste solo le prime tre classi sono utilizzate effettivamente su Internet. Una rete di classe A, ad esempio, usa il primo byte per indicare la rete, e i restanti tre byte per indicare i singoli nodi. Una rete di classe C invece usa i prime tre byte per indicare la rete e l'ultimo per l'host. Inoltre, poiché il riconoscimento del tipo di indirizzo viene effettuato sul primo byte, esistono dei vincoli sul valore che esso può assumere per ogni classe [75]. Per le reti di classe A i valori potranno andare da 1 a 127, per quelle di classe B da 128 a 191, per quelle di classe C da 192 a 223. Ne consegue che possono esistere solo 127 reti di classe A, a ciascuna delle quali però possono essere collegati ben 16.777.214 diversi computer [76]. Invece le reti di classe B (due byte per l'indirizzo) possono essere 16.384, ognuna delle quali può ospitare fino a 65.534 host. Infine le reti di classe C potranno essere 2.097.152, composte da un massimo di 254 host. Per capire meglio lo schema di indirizzamento di Internet basta pensare alla struttura di un normale indirizzo postale. Lo scriviamo come nei paesi anglosassoni, con il numero civico prima: 2, Vicolo Stretto, Roma, Italia. Anche qui abbiamo quattro blocchi di informazioni: 'Vicolo Stretto, Roma, Italia' svolge la funzione di un indirizzo di rete, '2' corrisponde all'indirizzo del computer. Un indirizzo di classe C! Per trovare una analogia con un indirizzo di classe A potremmo pensare a 'Presidenza della Repubblica, Italia'. L'analogia con il sistema postale è in realtà molto più profonda di quanto non potrebbe sembrare. Infatti il sistema di recapito dei pacchetti di dati attraverso la rete è funzionalmente simile al modo in cui un servizio postale tradizionale organizza il recapito delle lettere (anche queste in fondo sono pacchetti di dati). Pensiamo al sistema postale: quando imbuchiamo una lettera questa arriva all'ufficio postale locale; se la lettera reca sulla busta un indirizzo di destinazione di competenza di un altro ufficio postale, sarà inviata a quell'ufficio postale, che si preoccuperà di recapitarla al destinatario. Naturalmente l'ufficio postale locale non conosce gli indirizzi di tutti gli altri uffici postali locali del mondo. Se una lettera è indirizzata ad esempio in Francia, l'ufficio locale la spedirà prima all'ufficio nazionale delle poste, che a sua volta manderà tutta la corrispondenza indirizzata alla Francia al suo omologo francese, il quale farà procedere la nostra lettera verso l'ufficio postale locale, che infine la recapiterà al destinatario. Anche Internet funziona così. Quando infatti il protocollo IP di un computer riceve dei dati da inviare ad un certo indirizzo, per prima cosa guarda alla parte dell'indirizzo che specifica la rete. Se l'indirizzo di rete è quello della rete locale, i dati sono inviati direttamente al computer che corrisponde all'indirizzo. Se invece l'indirizzo di rete è esterno, i dati vengono inviati ad un computer speciale denominato gateway o router che gestisce il traffico di interconnessione (quello, cioè, diretto verso altre sottoreti), proprio come l'ufficio postale gestisce il recapito delle lettere. Ogni router ha in memoria un elenco (detto tabella di routing) degli indirizzi dei router competenti per le altre sottoreti che conosce direttamente, più uno per le destinazioni di cui non ha diretta conoscenza. [77] Quando riceve un pacchetto di dati da uno dei computer della sua sottorete, il router legge l'intestazione IP, dove è segnato l'indirizzo di destinazione, e poi lo invia al router competente per quell'indirizzo, che a sua volta lo trasmetterà al computer a cui esso era destinato. L'assegnazione effettiva degli indirizzi di rete viene curata da un organismo internazionale, l'Internet Assigned Number Authority (IANA), il quale a sua volta delega ad enti nazionali la gestione degli indirizzi di rete nei vari paesi. In Italia tale gestione è curata dalla Registration Authority italiana, che fa capo al CNR (ed è dunque funzionalmente collegata al Ministero dell'università e della ricerca scientifica e tecnologica), in base alle indicazioni fornite dalla Naming Authority italiana (che opera in stretto rapporto con il Ministero delle poste e delle telecomunicazioni). Tutte le indicazioni del caso, compresi i moduli necessari alla richiesta di registrazione per nuovi nomi di dominio, sono disponibili alla URL http://www.nic.it/RA. Fino al 1998 questo lavoro era svolto nell'ambito del GARR [78], ma l'espansione commerciale della rete Internet sta progressivamente portando anche in Italia a uno svincolamento delle procedure centrali di gestione della rete dal solo mondo della ricerca universitaria. Naturalmente la cura degli indirizzi di ogni singolo host è affidata ai gestori (o meglio system manager) delle varie reti. Ed è ovviamente importante che gli indirizzi assegnati ai vari host siano diversi l'uno dall'altro. Una conseguenza del complicato (ma efficiente) schema di indirizzamento di Internet è che gli indirizzi sono limitati. Tanto per farsi una idea: gli indirizzi di classe A sono stati esauriti da molto tempo, quelli di classe B quasi, e non vengono più assegnati, quelli di classe C sono assegnati al 50 per cento. Con gli attuali ritmi di crescita di Internet si corre seriamente il rischio di esaurire entro pochi anni tutti gli indirizzi disponibili. Per questa ragione è stata sviluppata recentemente una versione evoluta del protocollo IP, denominata 'IP Next Generation' o 'IP 6', basata, come si è accennato, su un sistema di indirizzamento a 128 bit. Le possibili combinazioni sono decisamente al di là del numero di abitanti del pianeta. Il prossimo collo di bottiglia, se mai ci sarà, verrà causato da amici alieni! Il nuovo protocollo IPNG è tra quelli inclusi nelle sperimentazioni di Internet II. Spedire dati a pacchettiInternet, si è detto, è una rete a commutazione di pacchetto. Questo significa che i dati sulla rete viaggiano in blocchi di dimensione definita: un datagramma IP per default occupa 1500 byte. Ma è chiaro che assai raramente i dati scambiati dagli utenti di Internet avranno dimensioni pari o inferiori a quelli dei piccoli pacchetti IP. Ad ovviare a questi limiti interviene il protocollo che gestisce l'organizzazione dei dati e il controllo della trasmissione, il Transmission Control Protocol (TCP). Se la dimensione del blocco di dati da inviare eccede la dimensione di un singolo pacchetto (come avviene di norma) il TCP è in grado di suddividerlo, in fase di invio, in una catena di pacchetti, e di ricomporlo in fase di ricezione. Quando il modulo TCP riceve dei dati da trasmettere da parte di una certa applicazione del livello superiore, suddivide il flusso di dati in una sequenza di pacchetti; ad ogni pacchetto viene aggiunta una intestazione (TCP header) che ne specifica il numero d'ordine e il tipo di applicazione che lo ha prodotto. In questo modo il TCP ricevente sarà in grado di ricomporre i dati nella loro sequenza originaria e di passarli alla applicazione giusta. Ma il TCP svolge anche un'altra importante funzione, come il nome stesso suggerisce: assicura che la trasmissione dei dati vada a buon fine, esercitando un controllo sulla comunicazione. Per fare questo il modulo TCP del computer A che invia stabilisce un contatto diretto con il suo pari (peer in termini tecnici) nell'host B che riceve. La comunicazione inizia con una richiesta rivolta da A a B di prepararsi a ricevere dati. In caso di risposta positiva A inizia il trasferimento del primo segmento di dati, e poi attende che B invii un segnale di conferma di aver ricevuto tutti i dati inviati. Se questo non avviene o se B dichiara di avere ricevuto solo una parte dei dati inviati, A ritrasmette il segmento perduto. Naturalmente questo schema semplifica il vero funzionamento delle transazioni TCP, e offre un'idea solo teorica delle comunicazioni in rete. L'essenziale è tuttavia che un meccanismo di questo tipo permette alla maggior parte delle comunicazioni su Internet di andare a buon fine; se pensate che ogni giorno avvengono in rete miliardi di transazioni, vi potrete rendere conto della efficienza e dell'importanza di questo sistema. I nomi dei computer su InternetIl metodo di indirizzamento numerico dell'Internet Protocol, sebbene sia molto efficiente dal punto di vista dei computer, che macinano numeri, è assai complicato da maneggiare per un utente. Ricordare le varie sequenze numeriche corrispondenti agli indirizzi dei computer a cui ci si intende connettere può essere molto noioso, come lo sarebbe dover ricordare a memoria tutti i numeri telefonici dei nostri amici e conoscenti. Per questo sono nate le agende: se voglio telefonare a Gino, cerco sulla mia agenda, magari elettronica, il suo nome e leggo il suo numero di telefono. Pensate, poi, quanto sarebbe comodo dire al telefono "voglio telefonare a Gino" e sentire il telefono comporre da solo il numero [79]. Proprio al fine di facilitare l'impiego della rete da parte degli utenti è stato sviluppato un sistema di indirizzamento simbolico, che funziona in modo simile: si chiama Domain Name Service (DNS). Attraverso il DNS ogni host di Internet può essere dotato di un nome (domain name), composto da stringhe di caratteri. Tali stringhe, a differenza dell'indirizzo numerico, possono essere di lunghezza illimitata. È evidente che per un utente utilizzare dei nomi simbolici è molto più semplice e intuitivo che maneggiare delle inespressive sequenze di numeri. Ad esempio, all'host 151.100.20.152 corrisponde il seguente nome: crilet.let.uniroma1.it. Come si può vedere, anche i nomi sono sequenze di simboli separati da punti. Questa articolazione rispecchia la struttura gerarchica del Domain Name Service. Esso suddivide l'intera rete in settori, denominati domini, a loro volta divisi in sottodomini, e così via per vari livelli; ogni sottodominio fa parte del dominio gerarchicamente superiore: alla base della piramide ci sono i singoli host. L'identificativo di un host riassume le varie gerarchie di domini a cui appartiene: ogni sottostringa rappresenta o un dominio, o un sottodominio, o il nome del computer. Ma l'ordine di scrittura è inverso all'ordine gerarchico! Suona complicato, ma non lo è. Vediamo più da vicino il nostro esempio. La parte di indirizzo più a destra nella stringa indica il dominio più alto della gerarchia, nel nostro caso 'it'. In genere, il livello più alto identifica il paese o, per gli Stati Uniti, il tipo di ente che possiede il computer in questione. Gli altri livelli della gerarchia, muovendosi da destra a sinistra, scendono per i vari sottodomini fino ad identificare uno specifico host. Così, nel caso sopra considerato 'uniroma1' si riferisce al dominio di rete dell'Università di Roma 'La Sapienza'; 'let' si riferisce al sottodominio della facoltà di Lettere di questa università, e infine 'crilet' è il nome del singolo host, che nel nostro caso prende il nome dal Centro Ricerche Informatica e Letteratura. Dunque un nome simbolico fornisce all'utente dotato di un minimo di esperienza una serie di informazioni che possono essere molto utili. Il numero e le sigle dei domini di primo livello sono fissati a livello internazionale e vengono gestiti da appositi organismi. Nell'ambito di ogni dominio di primo livello possono essere creati un numero qualsiasi di sottodomini, anche se ogni autorità nazionale di gestione del DNS può imporre delle regole particolari. Quando il DNS è stato sviluppato, Internet era diffusa, salvo rare eccezioni, solo negli Stati Uniti. Per questa ragione la rete venne suddivisa in sei domini, le cui sigle si caratterizzavano per il tipo di ente o organizzazione che possedeva gli host e le reti ad essi afferenti:
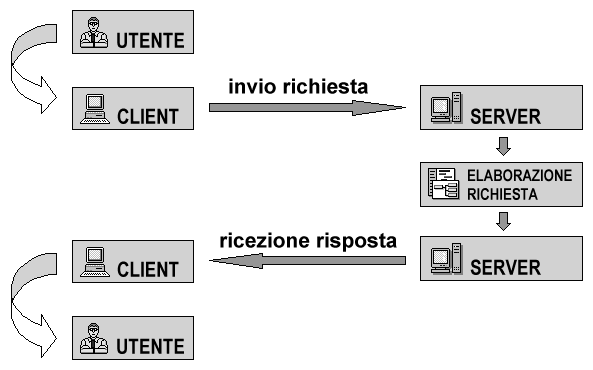
Quando la rete ha cominciato a diffondersi a livello internazionale sono stati creati altri domini di primo livello, suddivisi per nazioni: questi domini usano delle sigle che spesso (ma non sempre) corrispondono alle sigle delle targhe internazionali. L'Italia, come si può evincere dal nostro esempio, è identificata dalla sigla 'IT', l'Inghilterra dalla sigla 'UK', la Francia da 'FR', la Germania 'DE' e così via. Dal punto di vista tecnico il Domain Name Service è costituito da un sistema di database distribuiti nella rete chiamati name server, che sono collegati tra loro. Ogni dominio e ogni sottodominio ha almeno un name server di riferimento. Quest'ultimo svolge la funzione di tradurre i nomi in indirizzi numerici per conto degli host o di altri name server. Infatti la comunicazione effettiva tra gli host avviene sempre attraverso gli indirizzi numerici. La traduzione viene chiamata tecnicamente risoluzione. Quando un host (sollecitato da un utente o da una applicazione) deve collegarsi ad un altro host che ha un determinato nome simbolico, ad esempio sunsite.dsi.unimi.it, chiede al proprio name server locale di tradurre il nome simbolico nel corrispondente indirizzo numerico. Il name server locale va a vedere nella sua tabella se ha l'informazione richiesta. In caso positivo risponde all'host che lo ha interpellato, fornendo il corrispondente indirizzo numerico, altrimenti chiede ad un altro name server (detto name server di primo livello). La scelta di questo 'super-aiutante' è determinata dal dominio di primo livello dell'indirizzo da risolvere ('it', nel nostro caso). I name server di primo livello vengono detti authoritative name server. Essi possono sia rispondere direttamente, sia dirottare la richiesta a degli altri name server (questa volta di secondo livello). Il processo può continuare per vari sottolivelli, finché non viene risolto per intero l'indirizzo dell'host cercato. Intelligentemente, nel fare questo lavoro di interrogazione il nostro name server locale si annota gli indirizzi che ha conosciuto, in modo che le future richieste possano essere risolte immediatamente. Grazie a questo meccanismo il DNS è sempre aggiornato: infatti la responsabilità di aggiornare i singoli name server è automatica e decentralizzata e non richiede una autorità centrale che tenga traccia di tutti i milioni di host computer collegati a Internet. Come avviene per gli indirizzi, la gestione del sistema DNS in un dominio di primo livello viene affidata a degli enti specifici. Questi enti hanno il compito di assegnare i nomi di sottodominio e di host, curando attentamente che non esistano omonimie; essi inoltre debbono occuparsi di gestire il database principale del dominio di cui sono responsabili, e dunque di garantire il funzionamento del DNS a livello globale. In Italia l'ente che effettua la gestione del DNS primario è il medesimo che assegna gli indirizzi di rete numerici, la già ricordata Registration Authority, collegata al CNR e dunque - attraverso il MURST - al Governo. Anche negli Stati Uniti la gestione dei nomi veniva controllata da una agenzia federale. Ma la crescita della rete e la sua commercializzazione ha fatto di questa attività tecnico/amministrativa una possibile fonte di profitto. Per questo la sua gestione è stata recentemente privatizzata e assegnata ad una serie di società concessionarie, che impongono delle tariffe sulla registrazione di un nome e sulla sua associazione ad un indirizzo. Le applicazioni di rete e l'architettura client/serverLo strato dei servizi applicativi è l'ultimo livello nell'architettura del TCP/IP. A questo livello si pongono tutte le applicazioni che producono i dati e che fanno uso dei protocolli TCP e IP per inviarli attraverso la rete. Si tratta per la maggior parte delle applicazioni e dei servizi di rete con i quali gli utenti interagiscono direttamente. Come sappiamo Internet offre all'utente una molteplicità di servizi e di applicazioni che facilitano l'uso della rete e lo scambio o il reperimento di informazioni. Si va dalla posta elettronica allo scambio di file, fino alla diffusione in tempo reale di informazione multimediale. Ogni singolo servizio di rete Internet si basa su un dato protocollo, specifico di quel particolare servizio. Ma come funzionano le varie applicazioni che complessivamente sono presenti su Internet? I servizi telematici di Internet si basano su una particolare modalità di interazione, denominata tecnicamente architettura client-server. Con tale formula si indica in generale una applicazione informatica che è costituita da due moduli interagenti ma distinti, che collaborano tra loro per eseguire un certo compito richiesto dall'utente. Il client è un programma dotato di una interfaccia che consente all'utente di specificare le richieste di reperimento, elaborazione e visualizzazione dei dati, e si occupa di reperire, richiedere e presentare i dati conservati dal server, di cui deve anche conoscere il nome o l'indirizzo. Quest'ultimo invece si occupa solo dell'archiviazione e dell'invio dei dati al client che li ha richiesti. Durante una connessione il client, in seguito ad una azione dell'utente o a un evento programmato, invia una richiesta al server. Questo riceve la richiesta, verifica che siano soddisfatte le condizioni per esaudirla (autorizzazione all'accesso, correttezza sintattica del messaggio, etc.), e provvede ad agire di conseguenza, inviando i dati richiesti, eventualmente dopo averli sottoposti a dei processi di elaborazione. Quando i dati arrivano al client che li aveva richiesti, essi vengono ulteriormente elaborati al fine della loro presentazione, dopodiché il sistema si rimette in condizione di attesa.
Normalmente client e server sono installati su macchine diverse: il primo si trova sul computer locale utilizzato dall'utente finale (che ha quindi bisogno di conoscere il funzionamento della sua interfaccia). Il secondo si trova sul sistema remoto, e le sue operazioni sono del tutto invisibili all'utente, a meno che non si verifichi qualche errore o difetto di esercizio. Tuttavia nulla impedisce che entrambi i moduli si trovino sulla stessa macchina (questo avviene normalmente in tutte le macchine che ospitano i programmi server). Affinché l'interazione tra client e server possa essere effettuata, è necessario che entrambi utilizzino un linguaggio comune, ovvero un protocollo applicativo. Su Internet vengono utilizzati numerosi protocolli specifici delle applicazioni, uno per ogni servizio di rete: abbiamo ad esempio il Simple Mail Transfer Protocol (SMTP) per la posta elettronica, il File Transfer Protocol (FTP) per il trasferimento di file tra host, e il protocollo su cui si basa World Wide Web, denominato Hyper-Text Transfer Protocol (HTTP). Ovviamente tutti questi protocolli applicativi debbono appoggiarsi sui protocolli di rete TCP/IP e sul DNS per poter effettivamente scambiare richieste e messaggi attraverso la rete. La tipologia delle connessioni di reteAlla luce di quanto abbiamo visto in questo e nel precedente capitolo, possiamo individuare le seguenti tre condizioni affinché un computer sia collegato alla rete:
Il conseguimento di queste condizioni richiede diverse procedure a seconda del tipi di collegamento di cui si dispone. In questo paragrafo ci soffermeremo su tali procedure da un punto di vista teorico e non operativo. Nell'appendice 'Internet da zero', i lettori interessati potranno invece trovare le istruzioni da seguire per configurare operativamente un collegamento avendo a disposizione le risorse hardware e software di cui tipicamente dispone un normale utente Internet. Il collegamento di un computer può essere basato su diverse infrastrutture hardware. In generale possiamo suddividere tutti questi diversi sistemi e apparati in due categorie principali:
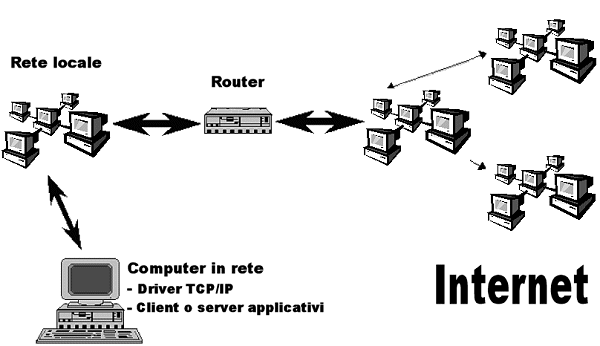
La connessione diretta ad Internet implica dei costi di investimento iniziali e di gestione piuttosto alti, in genere non alla portata del singolo utente, e interessa normalmente enti e aziende che vogliono entrare in rete come fornitori di informazioni e servizi. Le connessioni temporanee invece sono assai meno costose, e vengono di norma utilizzate da tutti quegli utenti che utilizzano la rete per periodi limitati e solo come ricettori di informazioni. In questo ambito l'ultimo decennio ha visto una vera e propria rivoluzione. Il collegamento direttoInternet, abbiamo ricordato più volte, è una rete costituita da un insieme di reti interconnesse. Per collegamento diretto si intende appunto l'inserimento di un computer all'interno di una di queste sottoreti locali, o la creazione di una nuova sottorete collegata ad Internet. Nel primo caso il procedimento è abbastanza semplice. Poiché esiste già una rete connessa ad Internet, è sufficiente aggiungere un computer a tale rete, e assegnare al nuovo host un indirizzo libero. Per indirizzo libero si intende uno degli indirizzi disponibili per la rete in questione non utilizzato da nessun altro host. Naturalmente questa operazione è possibile solo se il numero di computer collegati non ha esaurito il numero massimo di host consentiti. Ricordiamo che tale numero è determinato dalla classe della rete. Nel secondo caso il procedimento è un po' più complesso. In primo luogo occorre richiedere ad un fornitore di connettività abilitato (provider) la possibilità di allacciare una nuova sottorete. L'accesso normalmente viene affittato, ed ha costi variabili a seconda della larghezza di banda - ovvero della capacità dei cavi - e della classe di rete che si intende avere. In realtà attualmente sono disponibili per utenti privati solo reti di classe C, che possono ospitare fino a 254 singoli host. Se si intende collegare un numero maggiore di computer occorre dunque acquistare più reti di classe C. In secondo luogo occorre affittare o acquistare un cavo fisico che colleghi la nuova rete a quella del fornitore di accesso scelto. Si noti che non necessariamente la funzione di fornitore di accesso e quella di fornitore di cavo coincidono. In Italia ad esempio, per il momento, l'unico fornitore di infrastrutture fisiche è la Telecom Italia, mentre i fornitori di accesso commerciali sono diversi. Per collegare la nuova sottorete ad Internet è necessario avere un computer speciale che viene chiamato Internet router o Internet gateway. Questo dispositivo è il terminale del cavo di collegamento dedicato, ed è a sua volta collegato al router della rete del fornitore, già connesso ad Internet. Il traffico in entrata e uscita dalla nostra rete passerà attraverso questo 'cancello'.
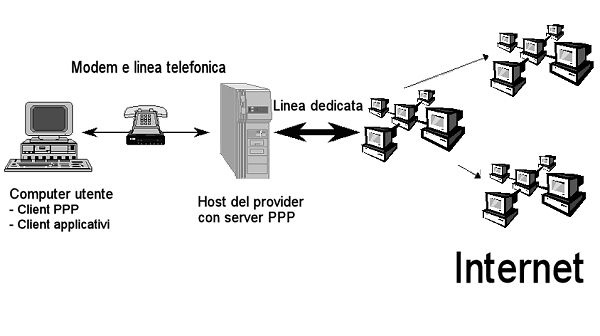
Le infrastrutture di rete usate nelle interconnessioni vanno dal cavo Ethernet o Token-ring, usati all'interno delle piccole sottoreti locali, fino alle dorsali continentali in fibra ottica. Come si diceva, i protocolli TCP/IP sono sostanzialmente indipendenti dalla tipologia dell'hardware usato nella connessione. Naturalmente dopo avere predisposto il collegamento fisico, bisognerà installare e configurare su tutti i computer che si vorrà collegare i driver TCP/IP (assegnando l'indirizzo IP) e i vari software client o server che si desidera utilizzare. In alternativa, è possibile anche assegnare un nome di dominio ai computer, richiedendolo all'autorità competente per l'assegnazione e registrandolo presso un DNS. Di norma tutti i fornitori di connettività a terzi si occupano delle pratiche necessarie a tale fine. Si noti che è possibile anche avere più di un nome di dominio per un singolo host. Infatti il DNS consente di associare più indirizzi simbolici ad uno stesso indirizzo IP. In questo modo lo stesso computer può rispondere, eventualmente fornendo diversi servizi, a più di un nome. A seconda del tipo di connettività che si possiede è anche possibile installare e gestire un sistema di DNS locale, che effettui la risoluzione dei nomi assegnati agli host della rete. Le operazioni di configurazione e di manutenzione di una rete non sono propriamente semplici. È necessario dunque disporre di figure professionali specifiche, gli amministratori di rete, che garantiscano la funzionalità della rete e che sappiano intervenire nel caso di problemi. L'accesso PPP su linea commutataFino a pochi anni fa l'utente finale che non aveva accesso ai centri di calcolo di enti e università dotate di collegamento diretto, poteva utilizzare i servizi di rete solo in via indiretta, collegandosi (via modem) ad un host mediante un software di emulazione terminale, e usando i programmi di rete installati su tale macchina (esattamente come su Internet avviene con il collegamento telnet). A partire dall'inizio degli anni 90 questo tipo di 'collegamenti mediati' è stato completamente rimpiazzato da una modalità di connessione assai più avanzata, che permette di collegare pienamente alla rete un computer anche senza disporre di linee dedicate. A tale fine sono stati sviluppati due protocolli: il Serial Line Internet Protocol (SLIP), poco efficiente e ormai in disuso, e il Point-to-Point Protocol (PPP), attualmente utilizzato dalla maggioranza degli utenti Internet. Il PPP permette di stabilire in modo dinamico una connessione TCP/IP piena utilizzando un collegamento di tipo 'punto/punto', che connette direttamente una macchina chiamante a un host gia connesso in rete. Rientrano in questo tipo di collegamenti le linee parallele, le linee seriali e il loro successore Universal Serial Bus (USB). Poiché attraverso queste linee è possibile connettere un computer ad una linea telefonica commutata (analogica o digitale), il protocollo PPP consente di collegare un computer alla rete anche senza disporre di una infrastruttura di rete dedicata e permanente. In effetti di norma esso viene utilizzato proprio per effettuare collegamenti Internet mediante modem e linea telefonica analogica, o adattatore ISDN e linea telefonica digitale.
Il PPP è un protocollo che si basa su una interazione client-server. Il server PPP viene installato su un computer dotato di una connessione diretta ad Internet e di una serie di modem connessi ad altrettante linee telefoniche. Esso inoltre deve avere a disposizione un certo 'pacchetto' di indirizzi IP disponibili. Il PPP infatti consente l'assegnazione dinamica degli indirizzi IP: quando un utente effettua la connessione, riceve un indirizzo che rimane assegnato al suo computer solo per il tempo della connessione, e che rimane poi libero per altri utenti. Il client PPP invece risiede sul computer che 'chiede' il collegamento. Tutti i sistemi operativi moderni ne sono dotati, e dispongono di interfacce notevolmente semplificate per configurare i parametri necessari alla connessione, alla portata anche di utenti inesperti (nell'appendice 'Internet da zero', comunque, vedremo le procedure per i sistemi operativi più diffusi). Esso si occupa di effettuare la telefonata al server e di gestire le transazioni di autenticazione: ogni client infatti è associato ad una coppia nome utente/password che gli permette di utilizzare i servizi del fornitore di accesso. Fintanto che la connessione rimane attiva, il computer chiamante diviene un nodo della rete a tutti gli effetti, con un suo indirizzo e dunque visibile dagli altri nodi. In teoria è possibile anche fornire dei servizi di rete, anche se a tale fine un computer dovrebbe essere sempre in linea. Poiché il collegamento con linea commutata si paga in ragione del tempo (almeno in tutte le nazioni europee) anche se la chiamata è urbana, mantenere aperta una connessione per periodi prolungati fa immediatamente alzare i costi delle bollette ben oltre le (pur care) tariffe dei collegamenti permanenti. Inoltre la linea commutata viene usata anche per le normali chiamate vocali, e dunque non può essere occupata troppo a lungo. Ma soprattutto la connessione su linea telefonica commutata presenta dei forti limiti in termini di velocità. Le linee analogiche permettono di arrivare con i modem più moderni ed efficienti (quelli dotati del protocollo V90) alla velocità teorica di circa 50 mila bps in entrata e 33 mila bps in uscita. Questi limiti, a dire il vero, si fanno sentire anche se il computer viene utilizzato per accedere ai servizi di rete. Infatti, la trasmissione di informazioni multimediali richiede lo spostamento di centinaia o migliaia di kilobyte, che, anche alle velocità massime attualmente supportate dalle connessioni via modem, obbligano ad attese molto lunghe. Un'alternativa più efficiente alla comunicazione su linee telefoniche analogiche è rappresentata dalla già citata tecnologia ISDN (Integrated Services Digital Network). Si tratta di un sistema di trasmissione digitale che si basa sul normale doppino telefonico e su speciali adattatori denominati ISDN Terminal Adaptor, e impropriamente chiamati 'modem ISDN'. L'accesso base ISDN è costituito da una coppia di linee a 64 mila bps, che consentono anche da una utenza domestica di arrivare a una velocità massima di 128 mila bps. I costi telefonici di questo accesso sono ormai allineati a quelli delle linee analogiche in tutti i paesi europei [80], mentre gli abbonamenti presso i provider di servizi Internet sono talvolta leggermente più cari. La commercializzazione di ISDN ha subito molti ritardi, e solo oggi sta iniziando a diffondersi, specialmente presso l'utenza professionale. Paradossalmente, il ritardo con cui è stata introdotta ha reso ISDN una tecnologia 'anziana' prima ancora che il suo impiego uscisse dalla fase sperimentale. I servizi di rete multimediali, infatti, richiedono già ora risorse assai più elevate. Una possibile soluzione, scartata per motivi di costi (almeno per ora) l'opportunità di cablare in fibra ottica anche le abitazioni private, potrà venire della tecnologia ADSL (Asymmetric Digital Subscriber Line, Linea Utente Digitale Asimmetrica). Sfruttando intensamente le tecniche di compressione dei dati, ADSL permette di ricevere dati a 8 milioni di bps e di inviare a 1 milione di bps (per questo viene definita 'asimmetrica') attraverso i normali cavi telefonici a doppino di rame. Inoltre ADSL, a differenza di ISDN, non è una linea commutata, ma permette di realizzare a basso costo un collegamento permanente, restando comunque in grado di veicolare comunicazioni vocali. La sua sperimentazione in alcune città è appena iniziata e si prevede che entro breve potrà essere commercializzata. Note [73] In realtà, l'esplosione recente di Internet ha messo a dura prova la capacità di indirizzamento di TCP/IP; come si è accennato parlando della storia e del futuro di Internet, le proposte di revisione del protocollo prevedono un notevole potenziamento proprio di queste capacità. [74] Il nome complessivo deriva dai due protocolli che hanno maggiore importanza: lo IP e il TCP. [75] Per la precisione il riconoscimento viene effettuato sui primi bit del primo byte. Ad esempio in una rete di classe A il primo bit deve essere 0. Dunque i numeri assegnabili vanno da '00000001' a '01111111', appunto, in notazione decimale, da '1' a '127'. In una rete di classe B i primi due bit devono essere 10; per una classe C i prime tre bit debbono valere 110. [76] Il calcolo è presto fatto: 256 elevato al numero di byte disponibili. A questo numero va sottratto due: infatti il primo (XYZ.0.0.0) e l'ultimo (XYZ.255.255.255) indirizzo di quelli disponibili per gli host sono riservati. [77] Normalmente i router conosciuti direttamente sono su parti contigue nella topologia di rete (che non necessariamente corrisponde alla contiguità geografica). [78] Il GARR, che sta per Gruppo Armonizzazione delle Reti di Ricerca (http://www.garr.net), è un ente che fa capo al Ministero dell'università e della ricerca scientifica e tecnologica, e che ha il compito di gestire e sviluppare la rete scientifica e universitaria italiana. In questo periodo, il GARR sta completando la transizione dei nodi universitari italiani verso la rete 'veloce' GARR-B (la 'velocità' di cui si parla resta comunque assai inferiore a quella degli analoghi progetti statunitensi). [79] Non si tratta di una possibilità irrealistica: per alcuni dei sistemi operativi più recenti sono disponibili programmi che consentono proprio questa operazione, e tale tecnologia ha iniziato a fare la sua comparsa anche negli apparecchi telefonici cellulari. [80] Nel momento in cui scriviamo, in Italia le tariffe per le telefonate urbane via ISDN sono le stesse di quelle applicate nel caso di linee telefoniche normali, e le tariffe per alcune destinazioni interurbane e intercontinentali sono addirittura lievemente più basse, ma il canone mensile da pagare è maggiore (uguale a quello relativo a due linee telefoniche normali; d'altro canto, un collegamento ISDN consente effettivamente di usufruire di una doppia linea in ricezione e trasmissione). |

![]()