La connessione tra reti e'fornita da stazioni multi-homed partcolari dette router o, impropriamente, gateways. Queste stazioni forniscono una interconnessione attiva tramite Protocolli di Routing o di Ricerca Percorso. Il compito di questi protocolli e'di riempire la tabella di routing, la quale viene usata dal protocollo IP.
In generale il compito dei protocolli di routing consiste di due parti: inizializzazione e manutenzione. La tabella di routing iniziale viene preparata allátto della partenza del protocollo. Il protocollo di routing mantiene aggiornata la tabella tramite continui interscambi di messaggi tra stazioni.
Non e'necessario che ogni stazione dell'internet, od ogni gateway, possieda informazioni complete sulla struttura di tutta la rete, sono sufficienti informazioni anche molto limitate.
Vale il concetto di gateway di default: i pacchetti che non possono venire inviati ad una stazione specifica, poiche'mancano informazioni al riguardo nella tabella di routing, vengono inviati al gateway di default.
Agli inizi la rete Internet (il nome ancora non esisteva) consisteva principalmente nella rete ARPAnet come dorsale principale, con qualche rete sussidiaria connessa tramite gateway principali d'accesso. Questi gateway venivano chiamati core gateways ed erano amministrati dallo Internet Network Operations Center, a differenza dei noncore gateways, amministrati da gruppi individuali.
La dorsale era il punto di smistamento unico e centrale per traffico in transito tra due sottoreti. I core gateways possedevano e si scambiavano informazioni complete sulla raggiungibilita' e percorso ottimale di tutte le sottoreti.
Tale architettura originaria e' stata abbandonata per tre ragioni principali:
L'introduzione di reti come la NSFnet (National Science Foundation) ha visto l'introduzione del concetto di peer backbone network (Reti Dorsali alla Pari).
Il routing tra dorsali alla pari pone particolari problemi:
Il protocollo GGP era usato dai core gateways originali. Non e' piu' parte essenziale dei protocolli TCP/IP.
GGP e' un esempio della classe di protocolli di routing detti Vector Distance. L'informazione scambiata tra nodi GGP consiste in un insieme di coppie (N,D) ove N e' un indirizzo IP di rete e D e' una distanza (metrica) misurata in salti tra reti, o meglio tra gateway. La metrica puo' essere artificialmente inflazionata per denotare reti lente.
Si dice che un gateway che usa GGP pubblicizza le reti che puo' raggiungere e il costo per raggiungerle.
Il primo byte di ciascun messaggio identifica il Tipo. Vi sono 5 tipi di messaggi:
Nel messaggio di aggiornamento al tipo e a un campo riservato segue un numero di Sequenza messaggio, inventato casualmente all'inizio e sempre solo incrementato; identifica il messaggio.
Le coppie (N,D) di informazioni sono per economia raggruppate per distanza, specificando i campi di Distanza e di Numero Reti alla Distanza data, che seguono.
Seguono gli indirizzi delle reti del gruppo; e' da notare che un indirizzo puo' essere lungo da uno a tre byte a seconda della sua classe. Il gruppo di indirizzi ad una distanza data e' poi ricondotto con un pad al confine di 32 bit.
Ad ogni invio di messaggio di aggiornamento il ricevente risponde con un messaggio di Conferma, positiva o negativa. Una conferma positiva porta il numero di sequenza del messaggio confermato, una conferma negativa ha il numero di sequenza dell'ultimo messaggio ricevuto correttamente.
I messaggi di echo permettono infine di verificare l'esistenza del protocollo corrispondente GGP su un gateway remoto.
Siti individuali possono avere una struttura arbitrariamente complessa in cui non e' possibile avere un core gateway per ogni singola rete interconnessa. Occorre quindi un meccanismo che consenta ai noncore gateways di informare il core gateway sull'esistenza e raggiungibilita' di reti nascoste.
Per il proposito del routing, un gruppo di reti e gateway controllate da una singola autorita' amministrativa e' detto un sistema autonomo (SA). Al suo interno, il sistema autonomo e' libero di scegliere qualunque metodologia di routing. Al limite, anche la dorsale ARPAnet e' un sistema autonomo. Spetta all'amministrazione del sistema autonomo garantire la consistenza del routing e a pubblicizzare la raggiungibilita' dei sistemi interni all'esterno.
Ad ogni sistema autonomo e' ufficialmente assegnato un Autonomous System Number
Due gateway collegati si dicono vicini interni se appartengono allo stesso sistema autonomo, e vicini esterni se appartengono a due diversi sistemi autonomi.
Il protocollo EGP e' usato da due gateway vicini esterni per scambiarsi informazioni di raggiungibilita' dei sistemi interni a ciascun SA. In particolare e' usato per inviare informazioni al Core sulla raggiungibilita' dei sistemi nei vari SA collegati.
EGP ha tre caratteristiche principali:
Tutti i messaggi EGP iniziano con una testata comune:

Dopo il campo Versione di EGP, segue il campo Tipo che identifica il tipo di messaggio, ed un campo Codice che dipende dal campo Tipo come sottospecifica. Il campo Statuo contiene informazioni che dipendono dal tipo.
Dopo il campo di controllo Checksum, calcolato col consueto algoritmo IP, segue l'Identificativo di Sistema Autonomo ed il numero di Sequenza del messaggio, per sincronizzare aggiornamenti e responsi.
Il campo codice identifica il tipo di messaggio:
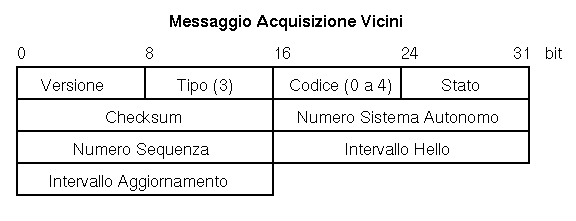
Il campo Intervallo Hello indica ogni quanto tempo in secondi testare se il vicino e' attivo. Il campo Intervallo di Polling e' in secondi e controlla l'intervallo minimo tra due messaggi di aggiornamento. Gli intervalli di polling possono essere asimmetrici e possono cambiare nel tempo.
Sono distinti due ruoli possibili, attivo e passivo. Una stazione attiva invia periodicamente messaggi di Hello e di Polling per determinare la raggiungibilita' dell'altra. Una stazione passiva invece, ispeziona il campo di Stato di un messaggio di raggiungibilita' inviatole.
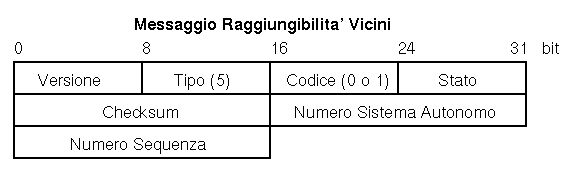
Il campo Codice 0 specifica un messaggio Hello, Codice 1 un messaggio I Heard You.
La perdita di un messaggio in transito non viene subito interpretata come irraggiungibilita'. EGP usa la regola del k-su-n: se k messaggi Hello consecutivi su n spediti non hanno la risposta I Heard You, allora la stazione remota viene dichiarata irraggiungibile. Similmente per il test di raggiungibilita'. Questa lentezza di responso e' per stabilizzare la rete: EGP usa un algoritmo Vector Distance, che risponde male a frequenti cambiamenti nello stato del routing. Percio' i messaggi di raggiungibilita' sono molto piu' frequenti dei messaggi di aggiornamento di routing.
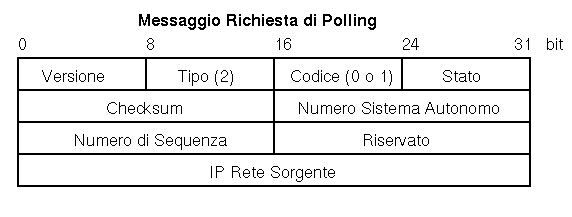
Il campo Rete Sorgente IP specifica una rete comune ai due sistemi autonomi a cui i due gateway EGP sono entrambi connessi: le distanze in salti sono misurate a partire da questa rete.
EGP permette di inviare informazioni di raggiungibilita' solo delle reti sottoposte al Sistema Autonomo del gateway inviante.
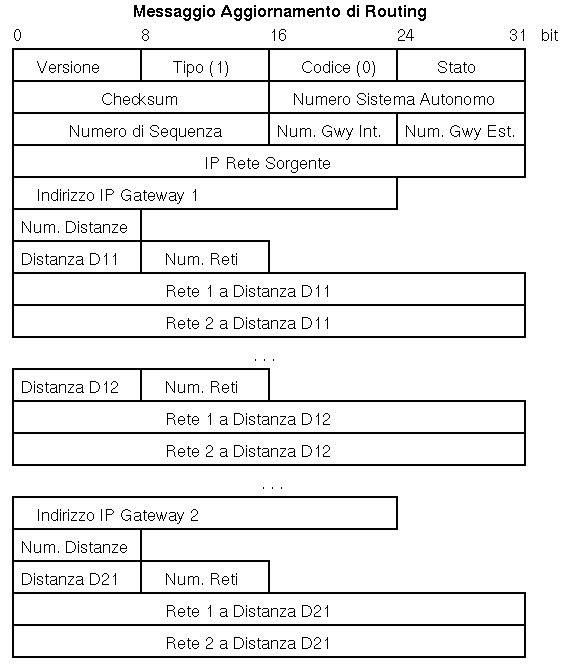
I campi # Gwy Int e # Gwy Est danno il numero rispettivamente dei gateway interni ed esterni che compaiono nel seguito del messagio. Poiche' non e' possibile compiere distinzioni nei dati, EGP invia due messaggi di Aggiornamento, uno per i gateway esterni ed uno per quelli interni.
I dati son divisi in gruppi per gateway e quindi suddivisi in gruppi per valore di Distanza. Le distanze sono misurate dalla Rete Sorgente IP di riferimento.
EGP non interpreta minimamente le metriche di distanza che riceve in un messaggio di Aggiornamento.
EGP passa solo informazioni di raggiungibilita' e quindi riconduce la topologia di rete ad un albero di cui la dorsale core e' la radice. Non vi sono modi di raggiungere altri sistemi autonomi se non attraverso il core.
Se il core gateway salta, viene a mancare l'intera connettivita' Internet del sistema autonomo. E' desiderabile configurare dei gateway di backup.
EGP non supporta il bilanciamento di carico su piu' gateway che uniscano due sistemi autonomi, ne' riesce a gestire la situazione di piu' reti Backbone presenti con richiesta di routing ottimale.
E' visibile in Internet una tendenza a staccarsi dal concetto di Dorsale Core e quindi anche di Sistema Autonomo come dipendente dal core.
Il raggruppamento di piu' sistemi autonomi richiede pochi cambiamenti ad EGP, in pratica principalmente la decisione su una conveniente trasformazione metrica.
Questa e' la definizione di uno offset da aggiungere alla normale metrica a salti, quando si passi da un sistema autonomo ad un altro. Il motivo e' di dare un vantaggio relativo intrinseco agli smistamenti entro un SA e di penalizzare alquanto gli attraversamenti di confine.
I protocolli Distance Vector sono relativamente semplici, molto diffusi, ma hanno parecchi inconvenienti pratici. Vengono spesso chiamati anche protocolli di Bellman-Ford.
Siano dati un certo numero di router, ciascuno connesso con uno o piu' link ai router vicini, a formare un internet (rete di reti di una certa complessita'), con anche dei loop chiusi. Ciascun router ha visibilita' diretta dei sui vicini immediati, acquisita tramite protocolli semplici, a interrogazione diretta, ed ha iniziato a compilare la sua tabella di routing.
Della tebella di routing interessano in partticolare i campi di Destinazione Finale, Destinazione Successiva e Metrica. La metrica e' calcolata semplicemente in numeri di salti tra gateway, ove la rete locale a recapito diretto ha metrica zero.
L'idea fondamentale di un protocollo Distance Vector e' che ogni router invia ai vicini la propria tabella di routing. Ogni router con i messaggi ricevuti aggiorna la propria tabella di routing e poi la propaga a sua volta ai vicini, incluso le informazioni ricevute da altri.
L'idea e' semplice ed e' un ottimo esempio di routing con informazione limitata, ma ha subito bisogno di alcuni aggiustamenti:
Le informazioni di aggiornamento vengono inviate da ciascun router quando viene notata una variazione della propria tabella di routing o anche a intervalli regolari. I protocolli che implementano questo algoritmo si preoccupano di sfasare casualmente i messaggi nel tempo per impedire intasamenti di rete.
E' facile verificare che un router che ha appena compiuto il boot in una rete con altri router presenti molto presto riceve informazioni sufficienti ad avere una tabella di routing aggiornata.
E' anche possibile verificare che molti router che salgono simultaneamente riescono, tramite interscambi di messaggi ripetuti, a convergere presto ad una rappresentazione comune della struttura di rete.
I problemi sorgono quando avvengono variazioni improvvise della struttura di rete (nuovi percorsi o la caduta di vecchi percorsi).
La stazione A che avverte la caduta di una rete X vicina pone una metrica infinita alla destinazione finale e si accinge ad inviare messaggi al vicino B. Se il vicino propaga le vecchie informazioni ad altri, tra cui C, prima di ricevere l'aggiornamento di distanza infinita, e C propaga ad A prima che A possa inviare a C la notifica di distanza infinita, allora A aggiornera' la propria tabella di routing indicando che la strada per X passa per C (poi per B poi per A): si e' creato un loop.
Non si tratta di una situazione impossibile, poiche' tutte le stazioni trasmettono aggiornamenti ad intervalli casuali. La stazione A non puo' non credere alla stazione C, poiche' non conosce come C (e poi B) intenda recapitare i messaggi ad X.
La situazione di loop verra' notata quando si verifica l'emissione di messaggi ICMP TTL Exceeded, e questi messaggi solleciteranno il protocollo di routing ad aggiornare le tabelle. Nel frattempo si e' verificata congestione di rete.
In un altro scenario piu' reti singole vengono a mancare improvvisamente, isolando tra loro due sezioni dell'internet. E' dimostrabile che i messaggi di routing non indicheranno subito la distanza infinita sulle reti cadute, ma una distanza gradualmente crescente fino al valore infinito, con tempi di convergenza anche piuttosto lunghi, e conseguente congestione. E la congestione ha una influenza negativa sulla stessa velocita' di convergenza.
Una strategia per eliminare i loop a due salti e mitigare i loop piu' complessi si chiama "split horizon with poisonous reverse" (orizzonte diviso con reciproco avvelenato ?!). Se A invia a B informazioni di raggiungibilita', B dopo aver aggiornato la propria tabella di routing la ripropaga ad A, ma ponendo metrica infinita a tutte le destinazioni finali che hanno A stesso come destinazione successiva.
Ogni stazione non solo invia aggiornamenti regolari ai vicini ma si aspetta anche di riceverli; se non vengono ricevuti aggiornamenti consecutivi per un certo numero di volte (tipicamente sei) l'intervallo medio di aggiornamenti, il router che non invia viene dichiarato irraggiungibile.
Da un lato questo tempo di grazia lungo e' desiderabile poiche' impedisce i falsi allarmi, ma dall'altro introduce un ritardo considerevole nell'aggiornamento dei cambiamenti di struttura di rete. Dopo la decisione di irraggiungibilita' il router che la compie entra in modalita' diversa: invia subito una notifica di aggiornamento ai vicini (triggered update) ed tutti i router coinvolti si scambiano i messaggi di update ad un ritmo molto superiore al normale, fino a convergenza avvenuta.
I protocolli Link State si basano sul concetto della mappa distribuita: tutti i nodi hanno una copia della mappa di rete, che viene aggiornata in continuazione.
Invece di distribuire alla rete un'idea dei percorsi migliori da seguire, viene distribuita la mappa della rete, e quindi ciascuna stazione puo' calcolare indipendentamente il percorso migliore.
La mappa della rete e' strutturata come un database in cui ciascun record rappresenta un link o connessione tra due router. Ogni record contiene il router di partenza, quello di arrivo, l'identificativo del link e la metrica o costo relativo da attribuire al link.
Il protocollo di diffusione dei messaggi di aggiornamento rete e' detto protocollo di flooding (alluvione), per la sua velocita' di propagazione dati.
Ogni messaggio del protocollo contiene una serie di record, ciascuno con la struttura:
Il messaggio nel suo complesso contiene anche un campo di Time Stamp o Numero Messaggio, per impedire che vecchi messaggi corrompano la base dati. Questo numero e' solitamente in un registro a 32 bit e compie il ciclo (modulo). Occorre una convenzione per stabilire univocamente quale tra due numeri sia maggiore.
Da parte di una stazione ricevente, l'algoritmo di flooding consiste nei seguenti passaggi:
L'operazione di propagazione del messaggio avviene verso tutti i vicini tranne quello che l'ha inviato.
La caduta di una o piu' connessioni viene riportata correttamente da ciascun nodo di rete vicino e propagata con l'algoritmo di flooding. Immediatamente le stazioni ricevono la nuova versione della struttura di rete, senza bisogno di convergenza.
Ora pero' l'acquisizione alla rete di un nuovo link tra due nodi puo' causare problemi di inconsistenza di versioni del database tra stazioni adiacenti.
L'allineamento del database tra stazioni adiacenti e' facilitato dall'esistenza di identificativi di link e di numeri di versione. Le due stazioni adiacenti devono mantenere per ciascun record di link solo la versione piu' aggiornata. La propagazione di ogni record di link sarebbe inefficiente poiche' molti record sarebbero gia' aggiornati nei due database adiacenti.
Molti protocolli Link State risolvono il problema in due passaggi: nel primo vengono inviati tutti i record di link ma con solo il numero di versione di ciascun record. Il ricevente compila una lista di record interesanti, il cui numero di versione e' piu' nuovo di quello del suo database e ne richiede la trasmissione completa con una Richiesta di Stato Link. Nella seconda fase vengono inviati per intero solo i record richiesti, che vengono poi propagati alle altre stazioni col normale algoritmo di flooding.
E' tipicamente necessario proteggere il database da vari tipi di corruzione, volontaria e involontaria. Tipiche protezioni sono:
Un protocollo Link State ha numerosi vantaggi su un protocollo Distance Vector, tra i quali
I protocolli Link State sono piu' facilmente scalabili. La complessita' di calcolo di tutti i percorsi possibili di una rete con N nodi cresce con ordine (N**2) per gli algoritmi Vector Distance, ma solo (N log N) per gli algoritmi Link State.