
Web servers frequently need some type of maintenance in order to operate at peak efficiency. This chapter will look at some maintenance tasks that can be performed by Perl programs. You will see some ways that your server keeps track of who visits and what Web pages are accessed on your site. You will also see some ways to automatically generate a site index, a what's new document, and user feedback about a Web page.
The most useful tool to assist in understanding how and when your Web site pages and applications are being accessed is the log file generated by your Web server. This log file contains, among other things, which pages are being accessed, by whom, and when.
Each Web server will provide some form of log file that records who and what accesses a specific HTML page or graphic. A terrific site to get an overall comparison of the major Web servers can be found at http://www.webcompare.com/. From this site one can see which Web servers follow the CERN/ncSA common log format that is detailed below. In addition, you can also find out which sites can customize log files, or write to multiple log files. You might also be surprised at the number of Web servers there are on the market.
Understanding the contents of the server log files is a worthwhile
endeavor. And in this section, you'll see several ways that the
information in the log files can be manipulated. However, if you're
like most people, you'll use one of the log file analyzers that
you'll read about in the section "Existing Log File Analyzing
Programs" to do most of your work. After all, you don't want
to create a program that others are giving away for free.
| Note |
This section about server log files is one that you can read when the need arises. If you are not actively running a Web server now, you won't be able to get full value from the examples. The CD-ROM that accompanies this book has a sample log file to you to experiment on but it is very limited in size and scope. |
Nearly all of the major Web servers use a common format for their log files. These log files contain information such as the IP address of the remote host, the document that was requested, and a timestamp. The syntax for each line of a log file is:
site logName fullName [date:time GMToffset] "req file proto" status length
Because that line of syntax is relatively meaningless, here is a line from a real log file:
204.31.113.138 - - [03/Jul/1996:06:56:12 -0800]
"GET /PowerBuilder/Compny3.htm HTTP/1.0" 200 5593
Even though I have split the line into two, you need to remember that inside the log file it really is only one line.
Each of the eleven items listed in the above syntax and example are described in the following list.
Implied Path and Filename-accesses a file in a user's home direc-tory. For example, /~foo/ could be expanded into /user/foo/homepage.html. The /user/foo directory is the home directory for the user foo. And homepage.html is the default file name for any user's home page. Implied paths are hard to analyze because you need to know how the server is set up and because the server's set up may change.
Relative Path and Filename-accesses a file in a directory that is specified relative to a user's home directory. For example, /~foo/cooking.html will be expanded into /user/foo/cooking.html.
Full Path and Filename-accesses a file by explicitly stating the full directory and filename. For example, /user/foo/biking/mountain/index.html.
Web servers can have many different types of log files. For example, you might see a proxy access log, or an error log. In this chapter, we'll focus on the access log-where the Web server tracks every access to your Web site.
In this section you see a Perl script that can open a log file and iterate over the lines of the log file. It is usually unwise to read entire log files into memory because they can get quite large. A friend of mine has a log file that is over 113 Megabytes!
Regardless of the way that you'd like to process the data, you must open a log file and read it. You can read the entry into one variable for processing, or you can split the entry into it's components. To read each line into a single variable, use the following code sample:
$LOGFILE = "access.log";
open(LOGFILE) or die("Could not open log file.");
foreach $line (<LOGFILE>) {
chomp($line); # remove the newline from $line.
# do line-by-line processing.
}
| Note |
If you don't have your own server logs, you can use the file server.log that is included on the CD-ROM that accompanies this book. |
The code snippet will open the log file for reading and will access the file one line at a time, loading the line into the $line variable. This type of processing is pretty limiting because you need to deal with the entire log entry at once.
A more popular way to read the log file is to split the contents of the entry into different variables. For example, Listing 21.1 uses the split() command and some processing to value 11 variables:
Turn on the warning option.
Initialize $LOGFILE with the full path and name of the access log.
Open the log file.
Iterate over the lines of the log file. Each line gets placed,
in turn, into $line.
Split $line using the space character as the delimiter.
Get the time value from the $date variable.
Remove the date value from the $date variable avoiding the time
value and the '[' character.
Remove the '"' character from the beginning of the request value.
Remove the end square bracket from the gmt offset value.
Remove the end quote from the protocol value.
Close the log file.
Listing 21.1 21LST01.PL-Read the Access Log and
Parse Each Entry
#!/usr/bin/perl -w
$LOGFILE = "access.log";
open(LOGFILE) or die("Could not open log file.");
foreach $line (<LOGFILE>) {
($site, $logName, $fullName, $date, $gmt,
$req, $file, $proto, $status, $length) = split(' ',$line);
$time = substr($date, 13);
$date = substr($date, 1, 11);
$req = substr($req, 1);
chop($gmt);
chop($proto);
# do line-by-line processing.
}
close(LOGFILE);
If you print out the variables, you might get a display like this:
$site = ros.algonet.se $logName = - $fullName = - $date = 09/Aug/1996 $time = 08:30:52 $gmt = -0500 $req = GET $file = /~jltinche/songs/rib_supp.gif $proto = HTTP/1.0 $status = 200 $length = 1543
You can see that after the split is done, further manipulation is needed in order to "clean up" the values inside the variable. At the very least, the square brackets and the double-quotes needed to be removed.
I prefer to use a regular expression to extract the information from the log file entries. I feel that this approach is more straightforward-assuming that you are comfortable with regular expressions-than the others. Listing 21.2 shows a program that uses a regular expression to determine the 11 items in the log entries.
Turn on the warning option.
Initialize $LOGFILE with the full path and name of the access log.
Open the log file.
Iterate over the lines of the log file. Each line gets placed,in turn, into $line.
Define a temporary variable to hold a pattern that recognizesa single item.
Use the matching operator to store the 11 items into pattern memory.
Store the pattern memories into individual variables.
Close the log file.
Listing 21.2 21LST02.PL-Using a Regular Expression
to Parse the Log File Entry
#!/usr/bin/perl -w
$LOGFILE = "access.log";
open(LOGFILE) or die("Could not open log file.");
foreach $line (<LOGFILE>) {
$w = "(.+?)";
$line =~ m/^$w $w $w \[$w:$w $w\] "$w $w $w" $w $w/;
$site = $1;
$logName = $2;
$fullName = $3;
$date = $4;
$time = $5;
$gmt = $6;
$req = $7;
$file = $8;
$proto = $9;
$status = $10;
$length = $11;
# do line-by-line processing.
}
close(LOGFILE);
The main advantage to using regular expressions to extract information is the ease with which you can adjust the pattern to account for different log file formats. If you use a server that delimits the date/time item with curly brackets, you only need to change the line with the matching operator to accommodate the different format.
One easy and useful analysis that you can do is to find out how
many times each document at your site has been visited. Listing
21.3 contains a program that reports on the access counts of documents
beginning with the letter s.
| Note |
The parseLogEntry() function uses $_ as the pattern space. This eliminates the need to pass parameters but is generally considered bad programming practice. But this is a small program, so perhaps it's okay. |
Turn on the warning option.
Define a format for the report's detail line.
Define a format for the report's header line.
Define the parseLogEntry() function.
Declare a local variable to hold the pattern that matches a single item.
Use the matching operator to extract information into pattern memory.
Return a list that contains the 11 items extracted from the log entry.
Open the logfile.
Iterate over each line of the logfile.
Parse the entry to extract the 11 items but only keep the file specification that was requested.
Put the filename into pattern memory.
Store the filename into $fileName.
Test to see if $fileName is defined.
Increment the file specification's value in the %docList hash.
Close the log file.
Iterate over the hash that holds the file specifications.
Write out each hash entry in a report.
Listing 21.3 21LST03.PL-Creating a Report of the
Access Counts for Documents that Start with the Letter S
#!/usr/bin/perl -w
format =
@<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<< @>>>>>>>
$document, $count
.
format STDOUT_TOP =
@|||||||||||||||||||||||||||||||||||| Pg @<
"Access Counts for S* Documents",, $%
Document Access Count
--------------------------------------- ------------
.
sub parseLogEntry {
my($w) = "(.+?)";
m/^$w $w $w \[$w:$w $w\] "$w $w $w" $w $w/;
return($1, $2, $3, $4, $5, $6, $7, $8, $9, $10, $11);
}
$LOGFILE = "access.log";
open(LOGFILE) or die("Could not open log file.");
foreach (<LOGFILE>) {
$fileSpec = (parseLogEntry())[7];
$fileSpec =~ m!.+/(.+)!;
$fileName = $1;
# some requests don't specify a filename, just a directory.
if (defined($fileName)) {
$docList{$fileSpec}++ if $fileName =~ m/^s/i;
}
}
close(LOGFILE);
foreach $document (sort(keys(%docList))) {
$count = $docList{$document};
write;
}
This program displays:
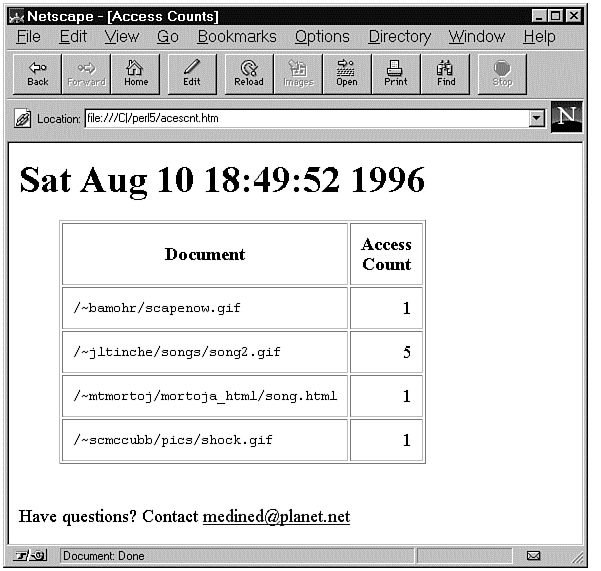
Access Counts for S* Documents Pg 1 Document Access Count -------------------------------------- ------------ /~bamohr/scapenow.gif 1 /~jltinche/songs/song2.gif 5 /~mtmortoj/mortoja_html/song.html 1 /~scmccubb/pics/shock.gif 1
This program has a couple of points that deserve a comment or two. First, notice that the program takes advantage of the fact that Perl's variables default to a global scope. The main program values $_ with each log file entry and parseLogEntry() also directly accesses $_. This is okay for a small program but for larger programs, you need to use local variables. Second, notice that it takes two steps to specify files that start with a letter. The filename needs to be extracted from $fileSpec and then the filename can be filtered inside the if statement. If the file that was requested has no filename, the server will probably default to index.html. However, this program doesn't take this into account. It simply ignores the log file entry if no file was explicitly requested.
You can use this same counting technique to display the most frequent remote sites that contact your server. You can also check the status code to see how many requests have been rejected. The next section looks at status codes.
It is important for you to periodically check the server's log file in order to determine if unauthorized people are trying to access secured documents. This is done by checking the status code in the log file entries.
Every status code is a three digit number. The first digit defines how your server responded to the request. The last two digits do not have any categorization role. There are five values for the first digit:
Table 21.1 contains a list of the most common status codes that
can appear in your log file. You can find a complete list on the
http://www.w3.org/pub/WWW/Protocols/HTTP/1.0/spec.html
Web page.
| Description Code | |
| OK | |
| No content | |
| Moved permanently | |
| Moved temporarily | |
| Bad Request | |
| Unauthorized | |
| Forbidden | |
| Not found | |
| Internal server error | |
| Not implemented | |
| Service unavailable |
Status code 401 is logged when a user attempts to access a secured document and enters an incorrect password. By searching the log file for this code, you can create a report of the failed attempts to gain entry into your site. Listing 21.4 shows how the log file could be searched for a specific error code-in this case, 401.
Turn on the warning option.
Define a format for the report's detail line.
Define a format for the report's header line.
Define the parseLogEntry() function.
Declare a local variable to hold the pattern that matches a single item.
Use the matching operator to extract information into pattern memory.
Return a list that contains the 11 items extracted from the log entry.
Open the logfile.
Iterate over each line of the logfile.
Parse the entry to extract the 11 items but only keep the site information and the status code that was requested.
If the status code is 401 then save the increment the counter for that site.
Close the log file.
Check the site name to see if it has any entries. If not, display a message that says no unauthorized accesses took place.
Iterate over the hash that holds the site names.
Write out each hash entry in a report.
Listing 21.4 21LST04.PL-Checking for Unauthorized
Access Attempts
#!/usr/bin/perl -w
format =
@<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<< @>>>>>>>
$site, $count
.
format STDOUT_TOP =
@|||||||||||||||||||||||||||||||||||| Pg @<
"Unauthorized Access Report", $%
Remote Site Name Access Count
--------------------------------------- ------------
.
sub parseLogEntry {
my($w) = "(.+?)";
m/^$w $w $w \[$w:$w $w\] "$w $w $w" $w $w/;
return($1, $2, $3, $4, $5, $6, $7, $8, $9, $10, $11);
}
$LOGFILE = "access.log";
open(LOGFILE) or die("Could not open log file.");
foreach (<LOGFILE>) {
($site, $status) = (parseLogEntry())[0, 9];
if ($status eq '401') {
$siteList{$site}++;
}
}
close(LOGFILE);
@sortedSites = sort(keys(%siteList));
if (scalar(@sortedSites) == 0) {
print("There were no unauthorized access attempts.\n");
}
else {
foreach $site (@sortedSites) {
$count = $siteList{$site};
write;
}
}
This program displays:
Unauthorized Access Report Pg 1 Remote Site Name Access Count --------------------------------------- ------------ ip48-max1-fitch.zipnet.net 1 kairos.algonet.se 4
You can expand this program's usefulness by also displaying the logName and fullName items from the log file.
Creating nice reports for your own use is all well and good. But suppose your boss wants the statistics updated hourly and available on demand? Printing the report and faxing to the head office is probably a bad idea. One solution is to convert the report into a Web page. Listing 21.5 contains a program that does just that. The program will create a Web page that displays the access counts for the documents that start with a 's.' Figure 21.1 shows the Web page that displayed the access counts.
Figure 21.1 : The Web page that displayed the Access Counts.
Turn on the warning option.
Define the parseLogEntry() function.
Declare a local variable to hold the pattern that matches a single item.
Use the matching operator to extract information into pattern memory.
Return a list that contains the 11 items extracted from the log entry.
Initialize some variables to be used later. The file name of the accesslog, the web page file name, and the email address of the web page maintainer.
Open the logfile.
Iterate over each line of the logfile.
Parse the entry to extract the 11 items but only keep the file specification that was requested.
Put the filename into pattern memory.
Store the filename into $fileName.
Test to see if $fileName is defined.
Increment the file specification's value in the %docList hash.Close the log file.
Open the output file that will become the web page.
Output the HTML header.
Start the body of the HTML page.
Output current time.
Start an unorder list so the subsequent table is indented.
Start a HTML table.
Output the heading for the two columns the table will use.
Iterate over hash that holds the document list.
Output a table row for each hash entry.
End the HTML table.
End the unordered list.
Output a message about who to contact if questions arise.
End the body of the page.
End the HTML.
Close the web page file.
Listing 21.5 21LST05.PL-Creating a Web Page to View
Access Counts
#!/usr/bin/perl -w
sub parseLogEntry {
my($w) = "(.+?)";
m/^$w $w $w \[$w:$w $w\] "$w $w $w" $w $w/;
return($1, $2, $3, $4, $5, $6, $7, $8, $9, $10, $11);
}
$LOGFILE = "access.log";
$webPage = "acescnt.htm";
$mailAddr = 'medined@planet.net';
open(LOGFILE) or die("Could not open log file.");
foreach (<LOGFILE>) {
$fileSpec = (parseLogEntry())[7];
$fileSpec =~ m!.+/(.+)!;
$fileName = $1;
# some requests don't specify a filename, just a directory.
if (defined($fileName)) {
$docList{$fileSpec}++ if $fileName =~ m/^s/i;
}
}
close(LOGFILE);
open(WEBPAGE, ">$webPage");
print WEBPAGE ("<HEAD><TITLE>Access Counts</TITLE></HEAD>");
print WEBPAGE ("<BODY>");
print WEBPAGE ("<H1>", scalar(localtime), "</H1>");
print WEBPAGE ("<UL>");
print WEBPAGE ("<TABLE BORDER=1 CELLPADDING=10>");
print WEBPAGE ("<TR><TH>Document</TH><TH>Access<BR>Count</TH></TR>");
foreach $document (sort(keys(%docList))) {
$count = $docList{$document};
print WEBPAGE ("<TR>");
print WEBPAGE ("<TD><FONT SIZE=2><TT>$document</TT></FONT></TD>");
print WEBPAGE ("<TD ALIGN=right>$count</TD>");
print WEBPAGE ("</TR>");
}
print WEBPAGE ("</TABLE><P>");
print WEBPAGE ("</UL>");
print WEBPAGE ("Have questions? Contact <A HREF=\"mailto:$mailAddr\ ">$mailAddr</A>");
print WEBPAGE ("</BODY></HTML>");
close(WEBPAGE);
Now that you've learned some of the basics of log file statistics, you should check out a program called Statbot, which can be used to automatically generate statistics and graphs. You can find it at:
http://www.xmission.com:80/~dtubbs/
Statbot is a WWW log analyzer, statistics generator, and database program. It works by "snooping" on the logfiles generated by most WWW servers and creating a database that contains information about the WWW server. This database is then used to create a statistics page and GIF charts that can be "linked to" by other WWW resources.
Because Statbot "snoops" on the server logfiles, it does not require the use of the server's cgi-bin capability. It simply runs from the user's own directory, automatically updating statistics. Statbot uses a text-based configuration file for setup, so it is very easy to install and operate, even for people with no programming experience. Most importantly, Statbot is fast. Once it is up and running, updating the database and creating the new HTML page can take as little as 10 seconds. Because of this, many Statbot users run Statbot once every 5-10 minutes, which provides them with the very latest statistical information about their site.
Another fine log analysis program is AccessWatch, written by Dave Maher. AccessWatch is a World Wide Web utility that provides a comprehensive view of daily accesses for individual users. It is equally capable of gathering statistics for an entire server. It provides a regularly updated summary of WWW server hits and accesses, and gives a graphical representation of available statistics. It generates statistics for hourly server load, page demand, accesses by domain, and accesses by host. AccessWatch parses the WWW server log and searches for a common set of documents, usually specified by a user's root directory, such as /~username/ or /users/username. AccessWatch displays results in a graphical, compact format.
If you'd like to look at all of the available log file analyzers, go to Yahoo's Log Analysis Tools page:
http://www.yahoo.com/Computers_and_Internet/Internet/
World_Wide_Web/HTTP/Servers/Log_Analysis_Tools/
This page lists all types of log file analyzers-from simple Perl scripts to full-blown graphical applications.
It is generally a good idea to keep track of who executes your CGI scripts. You've already been introduced to the environment variables that are available within your CGI script. Using the information provided by those environment variables, you can create your own log file.
Turn on the warning option.
Define the writeCgiEntry() function.
Initialize the log file name.
Initialize the name of the current script.
Create local versions of environment variables.
Open the log file in append mode.
Output the variables using ! as a field delimiter.
Close the log file.
Call the writeCgiEntry() function.
Create a test HTML page.
Listing 21.6 shows how to create your own CGI log file based on environment variables.
Listing 21.6 21LST06.PL-Creating Your Own CGI Log
File Based on Environment Variables
#!/usr/bin/perl -w
sub writeCgiEntry {
my($logFile) = "cgi.log";
my($script) = __FILE__;
my($name) = $ENV{'REMOTE_HOST'};
my($addr) = $ENV{'REMOTE_ADDR'};
my($browser) = $ENV{'HTTP_USER_AGENT'};
my($time) = time;
open(LOGFILE,">>$logFile") or die("Can't open cgi log file.\n");
print LOGFILE ("$script!$name!$addr!$browser!$time\n");
close(LOGFILE);
}
writeCgiEntry();
# do some CGI activity here.
print "Content-type: text/html\n\n";
print "<HTML>";
print "<TITLE>CGI Test</TITLE>";
print "<BODY><H1>Testing!</H1></BODY>";
print "</HTML>";
Every time this script is called, an entry will be made in the CGI log file. If you place a call to the writeCgiEntry() function in all of your CGI scripts, after a while you will be able perform some statistical analysis on who uses your CGI scripts.
So far we've been looking at examining the server log files in this chapter. Perl is also very useful for creating the Web pages that the user will view.
One of the most common features of a Web site is a What's New page. This page typically lists all of the files modified in the last week or month along with a short description of the document.
A What's New page is usually automatically generated using a scheduler program, like cron. If you try to generate the What's New page via a CGI script, your server will quickly be overrun by the large number of disk accesses that will be required and your users will be upset that a simple What's New page takes so long to load.
Perl is an excellent tool for creating a What's New page. It has good directory access functions and regular expressions that can be used to search for titles or descriptions in HTML pages. Listing 21.7 contains a Perl program that will start at a specified base directory and search for files that have been modified since the last time that the script was run. When the search is complete, an HTML page is generated. You can have your home page point to the automatically generated What's New page.
This program uses a small data file-called new.log-to
keep track of the last time that the program was run. Any files
that have changed since that date are displayed on the HTML page.
| Note |
This program contains the first significant use of recursion in this book. Recursion happens when a function calls itself and will be fully explained after the program listing. |
Turn on the warning option.
Turn on the strict pragma.
Declare some variables.
Call the checkFiles() function to find modified files.
Call the setLastTime() function to update the log file.
Call the createHTML() function to create the web page.
Define the getLastTime() function.
Declare local variables to hold the parameters.
If the data file can't be opened, use the current time as the default.
Read in the time of the last running of the program.
Close the data file.
Return the time.
Define the setLastTime() function.
Declare local variables to hold the parameters.
Open the data file for writing.
Output $time which is the current time this program is running.
Close the data file.
Define the checkFiles() function.
Declare local variables to hold the parameters.
Declare more local variables.
Create an array containing the files in the $path directory.
Iterate over the list of files.
If current file is current dir or parent dir, move on to next file.
Create full filename by joining dir ($path) with filename ($_).
If current file is a directory, then recurse and move to next file.
Get last modification time of current file.
Provide a default value for the file's title.
If the file has been changed since the last running of this program,open the file, look for a title HTML tag, and close the file.
Create an anonymous array and assign it to a hash entry.
Define the createHTML() function.
Declare local variables to hold the parameters.
Declare more local variables.
Open the HTML file for output.
Output the HTML header and title tags.
Output an H1 header tag.
If no files have changed, output a message.
Otherwise output the HTML tags to begin a table.
Iterate the list of modified files.
Output info about modified file as an HTML table row.
Output the HTML tags to end a table.
Output the HTML tags to end the document.
Close the HTML file.
Listing 21.7 21LST07.PL-Generating a Primitive What's
New Page
#!/usr/bin/perl -w
use strict;
my($root) = "/website/root"; # root of server
my($newLog) = "new.log"; # file w/time of last run.
my($htmlFile) = "$root/whatnew.htm"; # output file.
my($lastTime) = getLastTime($newLog); # time of last run.
my(%modList); # hash of modified files.
checkFiles($root, $root, $lastTime, \%modList);
setLastTime($newLog, time());
createHTML($htmlFile, $lastTime, \%modList);
sub getLastTime {
my($newLog) = shift; # filename of log file.
my($time) = time(); # the current time is the default.
if (open(NEWLOG, "<$newLog")) {
chomp($time = <NEWLOG>);
close(NEWLOG);
}
return($time);
}
sub setLastTime {
my($newLog) = shift; # filename of log file.
my($time) = shift; # the time of this run.
open(NEWLOG, ">$newLog") or die("Can't write What's New log file.");
print NEWLOG ("$time\n");
close(NEWLOG);
}
sub checkFiles {
my($base) = shift; # the root of the dir tree to search
my($path) = shift; # the current dir as we recurse
my($time) = shift; # the time of the last run of this script
my($hashRef) = shift; # the hash where modified files are listed.
my($fullFilename); # a combo of $path and the current filename.
my(@files); # holds a list of files in current dir.
my($title); # the HTML title of a modified doc.
my($modTime); # the modification time of a modfied doc.
opendir(ROOT, $path);
@files = readdir(ROOT);
closedir(ROOT);
foreach (@files) {
next if /^\.|\.\.$/;
$fullFilename = "$path/$_";
if (-d $fullFilename) {
checkFiles($base, $fullFilename, $time, $hashRef);
next;
}
$modTime = (stat($fullFilename))[9]; # only need the mod time.
$title = 'Untitled'; # provide a default value
if ($modTime > $time) {
open(FILE, $fullFilename);
while (<FILE>) {
if (m!<title>(.+)</title>!i) {
$title = $1;
last;
}
}
close(FILE);
%{$hashRef}->{substr($fullFilename, length($base))} =
[ $modTime, $title ];
}
}
}
sub createHTML {
my($htmlFile) = shift;
my($lastTime) = shift;
my($hashRef) = shift;
my($htmlTitle) = "What's New Since " . scalar(localtime($lastTime)). "!";
my(@sortedList) = sort(keys(%{$hashRef}));
open(HTML, ">$htmlFile");
print HTML ("<TITLE>$htmlTitle</TITLE>\n");
print HTML ("<HTML>\n");
print HTML ("<HEAD><TITLE>$htmlTitle</TITLE></HEAD>\n");
print HTML ("<BODY>\n");
print HTML ("<H1>$htmlTitle</H1><P>\n");
if (scalar(@sortedList) == 0) {
print HTML ("There are no new files.\n");
}
else {
print HTML ("<TABLE BORDER=1 CELLPADDING=10>\n");
print HTML ("<TR>\n");
print HTML (" <TH>Filename</TH>\n");
print HTML (" <TH>Modification<BR>Date</TH>\n");
print HTML (" <TH>Title</TH>\n");
print HTML ("</TR>\n");
foreach (sort(keys(%{$hashRef}))) {
my($modTime, $title) = @{%{$hashRef}->{$_}};
$modTime = scalar(localtime($modTime));
print HTML ("<TR>\n");
print HTML (" <TD><FONT SIZE=2><A HREF=\"$_\">$_</A></FONT></TD>\n");
print HTML (" <TD><FONT SIZE=2>$modTime</FONT></TD>\n");
print HTML (" <TD><FONT SIZE=2>$title</FONT></TD>\n");
print HTML ("</TR>\n");
}
print HTML ("</TABLE>\n");
}
print HTML ("</BODY>\n");
print HTML ("</HTML>\n");
close(HTML);
}
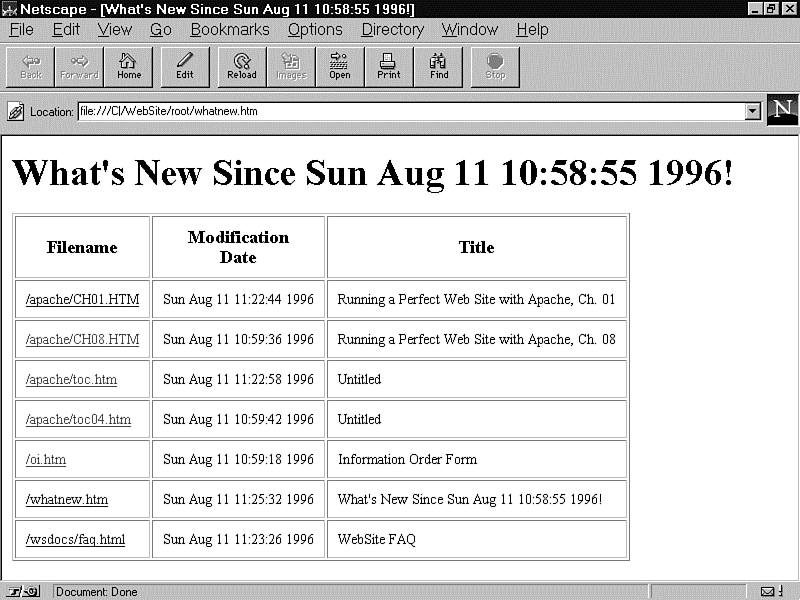
The program from Listing 21.7 will generate an HTML file that can be displayed in any browser capable of handling HTML tables. Figure 21.2 shows how the page looks in Netscape Navigator.
Figure 21.2 : A What's New page.
You might wonder why I end the HTML lines with newline characters when newlines are ignored by Web browsers. The newline characters will help you to edit the resulting HTML file with a standard text editor if you need to make an emergency change. For example, a document might change status from visible to for internal use only and you'd like to remove it from the What's New page. It is much easier to fire up a text editor and remove the reference then to rerun the What's New script.
I think the only tricky code in Listing 22.7 is where it creates an anonymous array that is stored into the hash that holds the changed files. Look at that line of code closely.
%{$hashRef}->{substr($fullFilename, length($base))} = [ $modTime, $title
The $hashRef variable holds
a reference to %modList that
was passed from the main program. The key part of the key-value
pair for this hash is the relative path and file name. The value
part is an anonymous array that holds the modification time and
the document title.
| Tip |
An array was used to store the information about the modified file so that you can easily change the program to display additional information. You might also want to display the file size or perhaps some category information. |
Using the relative path in the key becomes important when the HTML file is created. In order to create hypertext links to the changed documents, the links need to have the document's directory relative to the server's root directory. For example, my WebSite server has a base directory of /website/root. If a document changes in /website/root/apache, then the hypertext link must use /apache as the relative path in order for the user's Web browser to find the file. To arrive at the relative path, the program simply takes the full path and filename and removes the beginning of the string value using the substr() function.
You might also want to know a bit about the recursive nature of the checkFiles() function. This book really hasn't mentioned recursive functions in any detail yet. So, I'll take this opportunity to explain them.
A recursive function calls itself in order to get work done. One classic example of recursiveness is the factorial() function from the math world. 3! (five factorial) is the same as 1*2*3 or 6. The factorial() function looks like this:
sub factorial {
my($n) = shift;
return(1) if $n == 1;
return($n * factorial($n-1));
}
Now track the value of the return statements when factorial(3) is called:
First, the function repeated calls itself (recurses) until an
end condition is reached. When the end condition is reached ($n
== 1) then the stack of function calls is followed backwards to
read the final value of 6.
| Caution |
It is very important for a recursive function to have an end condition. If not, the function recurses until your system runs out of memory. |
If you look back at the checkFiles() function, you see that the end condition is not explicitly stated. When a directory has no subdirectories, the function will stop recursing. And instead of returning a value that is used in a mathematical expression, a hash reference is continually passed where the information about changed files is stored.
While the topic is the information about the changed files, let me mention the two directories that are used as parameters for checkFiles(). The first directory is the path to the Web server root-it will not change as the recursion happens. The second directory is the directory that the function is currently looking at. It will change with each recursion.
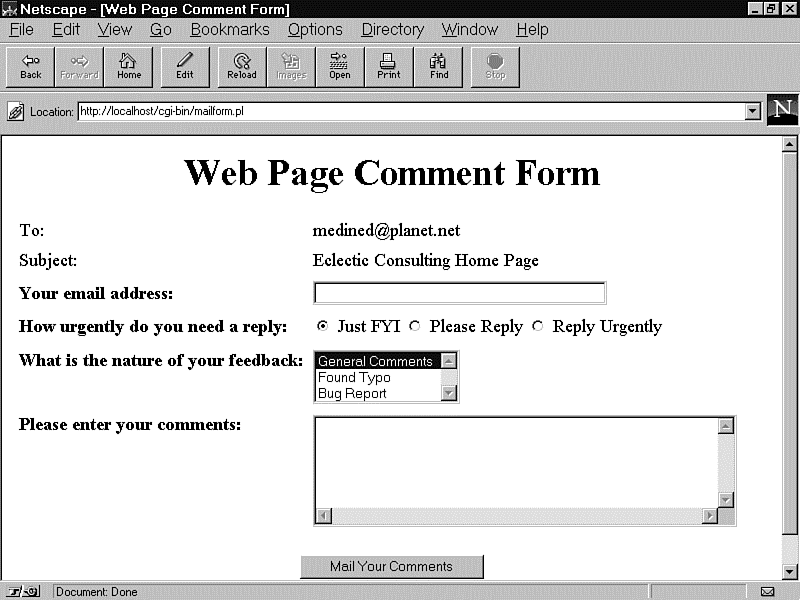
One of the hallmarks of a professional Web site, at least in my opinion, is that every page has a section that identifies the organization that created the page and a way to provide feedback. Most Web sites simply place a little hypertext link that contains the Webmaster's e-mail address. However, this places a large burden on the user to adequately describe the Web page so that the Webmaster knows which one they are referring to. Wouldn't it be nice if you could automate this? Picture this scenario: the user clicks a button and a user feedback form appears that automatically knows which page the user was on when the button was pressed. Perhaps the feedback form looks like Figure 21.3.
Figure 21.3 : A sample user feedback form.
You can have this nice feature at your site with a little work by following these steps:
In step one, you need to add a small HTML form to each Web page at your site. This form does not have to be very complex; just one button will do. You can get started by adding the following form to the bottom of your home page just before the </BODY> tag.
<FORM METHOD=POST Action="cgi-bin/feedback.pl">
<INPUT TYPE=hidden NAME="to" VALUE="xxxxxxxxxxxxxxxxxx">
<INPUT TYPE=hidden NAME="subject" VALUE="Home Page">
<CENTER>
<INPUT TYPE=submit VALUE="Send a comment to the webmaster">
</CENTER>
</FORM>
| Note |
You might need to change directory locations in the action clause to correspond to the requirements of your own server. |
The first field, to, is the destination of the feedback information. Change the xs to your personal e-mail address. The second field, subject, is used to describe the Web page that the HTML form is contained on. This is the only field that will change from Web page to Web page. The last item in the form is a submit button. When this button is clicked, the feedback.pl Perl script will be invoked.
This HTML form will place a submit button onto your home page like the one shown in Figure 21.4.
Figure 21.4 : The customized submit button.
| Note |
In the course of researching the best way to create a customized feedback form, I pulled information from a CGI script (mailer.cgi) by Matt Kruse (mkruse@saunix.sau.edu) and Serving the Web, a book by Robert Jon Mudry. |
Step Two requires you to create the feedback Perl script. Listing 21.8 contains a bare-bones script that will help you get started. This script will generate the HTML that created the Web page in Figure 21.3.
Turn on the warning option.
Turn on the strict pragma.
Declare a hash variable to hold the form's data.
Call the getFormData() function.
Output the web page's MIME type.
Output the start of the web page.
Output the feedback form.
Output the end of the web page.
Define the getFormData() function.
Declare a local variable to hold hash reference in parameter array.
Declare and initialize buffer to hold the unprocessed form data.
Declare some temporary variables.
Read all of the form data into the $in variable.
Iterate over the elements that result from splitting the input buffer using & as the delimiter.
Convert plus signs into spaces.
Split each item using the = as a delimiter.
Store the form data into the hash parameter.
Listing 21.8 21LST08.PL-How to Generate an On-the-Fly
Feedback Form
#!/usr/bin/perl -w
use strict;
my(%formData);
getFormData(\%formData);
print "Content-type: text/html\n\n";
print("<HTML>");
print("<HEAD><TITLE>Web Page Comment Form</TITLE></HEAD>\n");
print("<BODY>\n");
print("<H1 ALIGN=CENTER>Web Page Comment Form</H1>\n");
print("<FORM METHOD=\"POST\" Action=\"mailto:$formData{'to'}\">\n");
print("<TABLE CELLPADDING=3>");
print("<TR><TD>To:</TD><TD>$formData{'to'}<TD></TR>\n");
print("<TR><TD>Subject:</TD><TD>$formData{'subject'}</TD></TR>\n");
print("<TR>");
print("<TD><B>Your email address:</B></TD>");
print("<TD><INPUT TYPE=\"text\" NAME=\"addr\" SIZE=40 MAXLENGTH=80></TD>");
print("</TR>\n");
print("<TR><TD VALIGN=top><B>How urgently do you need a reply:</B></TD>\n");
print("<TD><INPUT TYPE=\"radio\" NAME=\"urgency\" VALUE=\"fyi\" CHECKED>
Just FYI\n");
print("<INPUT TYPE=\"radio\" NAME=\"urgency\" VALUE=\"plr\"> Please
Reply\n");
print("<INPUT TYPE=\"radio\" NAME=\"urgency\" VALUE=\"rur\"> Reply Urgently</TD><TR>\n");
print("<TR><TD VALIGN=top><B>What is the nature of your feedback:</B></TD>\n");
print("<TD><SELECT NAME=\"nature\" SIZE=3 MULTIPLE>\n");
print("<OPTION SELECTED>General Comments\n");
print("<OPTION> Found Typo\n");
print("<OPTION> Bug Report\n");
print("</SELECT></TD></TR>\n");
print("<TR><TD VALIGN=top><B>Please enter your comments:</B></TD>\n");
print("<TD><TEXTAREA NAME=\"comment\" COLS=50 ROWS=5></TEXTAREA></TD></TR>\n");
print("</TABLE><P>");
print("<CENTER><INPUT TYPE=\"submit\" VALUE=\"Mail Your Comments\"></CENTER>\n");
print("</FORM>");
print("</BODY>");
print("</HTML>");
sub getFormData {
my($hashRef) = shift; # ref to hash to hold form data.
my($in) = ""; # buffer for unprocessed form data.
my($key, $value); # temporary variables.
read(STDIN, $in, $ENV{'CONTENT_LENGTH'});
foreach (split(/&/, $in)) {
s/\+/ /g;
($key, $value) = split(/=/, $_);
%{$hashRef}->{$key} = $value;
}
}
This form will send all of the information from the feedback form to your e-mail address. Once there you need to perform further processing in order to make use of the information. You might want to have the feedback submit button call a second CGI script that stores the feedback information into a database. The database will make it much easier for you to track the comments and see which Web pages generate the most feedback.
The getFormData() function does not do a very good job of processing the form data. Chapter 20, "Form Processing" describes more robust methods of processing the data. This function was kept simple to conserve space.
Perl is an excellent tool to use when maintaining a Web site. There are many tasks that can be automated such as analysis of server logs and automatically generating HTML pages.
Server log files are created and maintained by Web servers for a variety of reasons. They are created to monitor such things as HTTP requests, CGI activity, and errors. Most Web servers use a common log file format so programs written to support one server will usually work on another.
Each log file entry in the access log holds information about a single HTTP request. There is information such s the remote site name, the time and date of the request, what documents was requested, and the server's response to the request.
After reading about the log file format, you saw an example that showed how to read a log file. The sample program evolved from simply opening the log file and reading whole lines to opening the log file and using a regular expression to parse the log file entries. Using regular expressions lets you modify your code quickly if you move to another server that has a nonstandard log file format.
The next sample program showed how to count the number of times each document has been accessed. This program uses the reporting features of Perl to print a formatted report showing the document and the number of accesses. A hash was used to store the document names and the number of accesses.
The status code field in the log file entries is useful. Especially, when you need to find out if unauthorized users have been attempting to access secured documents. Status codes are three digits numbers. Codes in the 400-499 range indicate problems on the client side. These are the numbers to watch if you think someone is trying to attack your site. Table 21.1 lists the most common status codes.
The next topic covered is converting a program that uses a report into a program that generates Web pages. Instead of using format statements, HTML tables were used to format the information.
There is no need for you to create Perl scripts to do all of the analyzing. Some programmers have already done this type of work and many of them have made their programs available on the Web for little or no cost. You can find a complete list of these analysis programs at:
http://www.yahoo.com/Computers_and_Internet/Internet/
World_Wide_Web/HTTP/Servers/Log_Analysis_Tools/
At times creating your own log file is good to do. You might want to track the types of Web browsers visiting your site. Or you might want to track the remote site addresses. Listing 21.6 showed how to create your own log file.
The next major topic was communicating with your users. Of course, communication is done through a variety of Web pages. One very popular feature is a What's New page. This page is typically changed every week and lets the user see what has changed in the past week. Listing 21.7 showed a sample program that generates the HTML for a What's New page. The program uses a data file to remember the last time that it was run.
Another popular feature is the user feedback form. With a little forethought, you can have the feedback automatically generated by a CGI script. Listing 21.8 shows how to generate a form when the user clicks a feedback button. This simple program can be expanded as needed to generate different forms based on which Web page the user clicked feedback on. You need to create a second CGI script to process the results of the feedback form.
The next chapter, "Internet Resources," will direct you to some resources that are available on the Internet. The chapter covers Usenet Newsgroups, Web sites, and the IRC.
Answers to Review Questions are in Appendix A.




{kind=link}
{kind=link}
{kind=link}
{kind=link}