 Copyright
©1996, Que Corporation. All rights reserved. No part of this book
may be used or reproduced in any form or by any means, or stored in a database
or retrieval system without prior written permission of the publisher except
in the case of brief quotations embodied in critical articles and reviews.
Making copies of any part of this book for any purpose other than your
own personal use is a violation of United States copyright laws. For information,
address Que Corporation, 201 West 103rd Street, Indianapolis,
IN 46290 or at support@mcp .com.
Copyright
©1996, Que Corporation. All rights reserved. No part of this book
may be used or reproduced in any form or by any means, or stored in a database
or retrieval system without prior written permission of the publisher except
in the case of brief quotations embodied in critical articles and reviews.
Making copies of any part of this book for any purpose other than your
own personal use is a violation of United States copyright laws. For information,
address Que Corporation, 201 West 103rd Street, Indianapolis,
IN 46290 or at support@mcp .com.
Notice: This material is excerpted from Special Edition Using Microsoft Exchange Server, ISBN: 0-7897-0687-3. The electronic version of this material has not been through the final proof reading stage that the book goes through before being published in printed form. Some errors may exist here that are corrected before the book is published. This material is provided "as is" without any warranty of any kind.
At one time or another, everyone has experienced having to sit tight and wait—for example, at the doctor's office, or in traffic jams at rush hour. At such times, life seems to move too slowly. The same can happen with respect to computer operations that seem to take forever. In particular, this chapter discusses what situations can cause Exchange to operate sluggishly. Your time, and that of your users, is precious. The sections in this chapter give you tools to solve your problems. You also learn some answers to that simple question, "How many users can Exchange support?"
This chapter also touches on capacity planning so that your server and network can stay ahead of their workload.
![]()
The examples presented in this chapter might not completely match your environment. It is extremely important you recognize your environment's unique elements, and move with the most appropriate tuning strategy.
![]()
I this chapter, you will learn the following:
The "Art" of Performance Tuning
As you may have heard before, tuning is more of an art than a science. There are no mystic techniques that detect and tune all Exchange servers in all situations. A majority of the time, you'll find yourself learning how individual system components work together producing a result. Then, you must consider the trade offs between the different results. For example, you may want to adjust your system components to provide more stability at the cost of slower performance.
Defining Users
Before you can answer the question, "How many users can an Exchange server support?", you need to understand the types of Exchange users in your organization.
Their usage pattern can range from reading and generating a few messages each week to hundreds every day. A small percentage of the user population, therefore, can be responsible for a majority of usage. It's a bit like driving in the left lane on the highway when you encounter some traffic. There's always one slow poke that seems to cause the traffic to slow down.
Overall, you must understand the different types of users (light or heavy) within your organization, as well as their daily tasks.
Obviously, each organization has purchased hardware specifically for its business needs. Consider a centralized company with one main location, and serveral warehouses and sales offices distributed throughout the country. The firm might house most of its computing power in corporate headquarters in the form of high end servers. The company then places cheaper, low end machines in the remote offices. The high end servers meet the needs of power users in headquarters, while remote field personnel are satisfied with low end machines to dial into and receive e-mail.
Another company might have serveral independent business units throughout the country. In this firm, middle end servers are used to provide computing power as close to the customer as possible. Therefore, each business unit can provide the fastest service.
You need to understand your company's use of server resources, as well as distinguish between low and high end machines (CPU speed, and RAM) as defined by your organization.
When monitoring a server, you will notice its workload rising as more users connect and begin to work on it. In addition, you might notice other remote servers connecting to the server (through Exchange's connectors), therefore generating even more load. However, the remote servers have users connecting and asking their local servers to perform remote tasks. These remote user requests are generating the load on your local server.
All server load, therefore, is ultimately generated by users' requests.
When users ask the server to open an unread message, they cause the server to perform that task as a direct result of the users' request. As such, a server's workload rises in direct proportion to the number of users working directly with it. On an Exchange server that is only serving users, direct requests make up most of the load. Direct requests are also synchronous in nature. As illustrated in figure 22.1, all elements of the request initiate by user requests and are completed in the proper sequence.
Fig. 22.1
All elements of a Direct Request are completed in the order in which they are received.
Background requests occur when a server is performing a task related to or on behalf of a user's request. Some examples of these tasks include replicating public folders and directory service information, expanding distribution lists, performing background maintenance, and transferring and delivering mail messages. Similar to direct requests, the load due to background requests is still proportional to the number of users directly connected. However, background requests occur asynchronously. Users, therefore, do not need to be directly connected to initiate this work.
In the context of background requests, delivering mail places most of the load on the server. The resources consumed for message delivery are directly proportional to the volume of mail generated by your users. Therefore, accurately determining what types of "users" are within your organization is key to tuning Exchange.
Remember, direct and background requests create different types of load on the server. You can measure this with the tools that this chapter describes.
How Many Users Can Exchange Support?
When a user initiates a request, the server uses one or more of its hardware resources to complete the task. Some examples of resources are the CPU, Memory, and the Network Card. Suppose a request requires one second of CPU time and two seconds of disk time—and that these cannot overlap. Assume also there are no other process that will interfere with this request's execution. The disk, therefore, is the "bottleneck" of the operation as it is the resource that expends the most time during a request's execution.
For example, two users issue the same request. Each request arrives at the server spaced three seconds apart. Each will be serviced and each user will not notice any unusual delays (other than the typical three second response).
If the second request arrives one second earlier, however, a bottleneck momentarily forms as the server is placed under a slightly heavier load. Consequently, the second user notices a slightly longer, (one second), delay in response time.
Once users begin to connect, and requests begin to queue up, the bottleneck becomes more pronounced. The server will experience a greater load, and there will be some unhappy users.
The point at which server load increases and response time becomes unacceptable, is when youŐve reached the number of users Exchange, given the hardware, can support.
Three variables exist that will affect response time:
As the number of user requests grows, so does response time. The same relationship is true for users per server. Hardware capacity has the opposite relationship: As it increases, so does its capability to handle more users and requests, therefore decreasing response time.
The next section shows you how to make your operation more efficient by tuning existing resources and planning for your users' demands.
Using Exchanges Performance Tuning Tools
Three tools exist that can help you tune your server, reduce response time, and make your operation more efficient.
![]()
For best results, use Loadsim after employing Performance Optimizer and Performance Monitor.
![]()
The Performance Optimizer automatically analyzes and optimizes key hardware for the best performance with Exchange.
The Optimizer first analyzes the server's logical drives. Then, it determines the most effective location for the MTA, information store, directory, and transaction log files. Specifically, the Optimizer locates the logical drive with the quickest sequential access time, and uses it for the transaction log files. The Optimizer then locates the logical drive with the fastest random access and use it for the server's particular role. For example, a dedicated backbone server moving messages to other sites reserves its swiftest random access drive for MTA files. A public folder-only server will use its hard drive for the public information store files. Keep in mind that the Performance Optimizer can only examine a drive down to the logical, not the physical level. If you have divided your physical hard drive into sections or you have partitioned a RAID array into multiple logical drives, the Performance Optimizer cannot provide a drive configuration that will give you increased performance.
The Performance Optimizer also analyzes the total amount of physical RAM and determines the necessary amount of memory for the directory and information store.
Although you can run the Performance Optimizer immediately after setup, you should consider running it again after the following changes:
An Exchange system should be structured so its resources are used efficiently and distributed fairly among the users. Performance Monitor (Perfmon) monitors specific system resources so you can meet your system structure goals.
Many times, you might be motivated to solve all problems the instant they appear. In fact, you might find your motivation dramatically increasing when users loudly display their unhappiness. To be prepared for such problems, you should first review Perfmon before moving too quickly in one direction. This can be accomplished by using the set of overview counters. Presented later in the chapter, these counters will keep you from plunging too quickly and deeply into a dilemma, only to discover that you've missed the problem. When your system is under a load you want to monitor, bring up all the overview counters in Perfmon. Then, you can determine which resource is being overworked.
Each section that follows has been listed in order of influence to Exchange's performance. Within each section, each counter is listed in the format Object: Counter. This will help you to locate the particular counter within the Performance Monitor.
![]()
The How to Detect and What to Do sections presented a little later are by no means exhaustive. You might determine, for example, that you don't have enough RAM for Exchange, and that the suggestions listed in these sections do not adequately address the issue. You will want to investigate the issue further by referencing the Optimizing Windows NT volume included in the NT Resource Kit.
![]()
With most Exchange systems, the disk subsystem has the most influence on performance.
The primary consideration with the disk subsystem is not size but the ability to handle multiple random reads and writes quickly. For example, when Exchange users open their Inbox, the set of properties in the default folder view must be read for approximately the first 20 messages. If the property information is not in the cache, it must be read from the information store on disk. Likewise, a message transferred from one server to another must be written to disk before the receiving server acknowledges receipt of the message. This is a safety measure to prevent message loss during power outages. Now imagine the read and write activity of 300 heavy e-mail users on one server. Their combined requests would generate a multitude of random traffic on the disk subsystem.
![]()
Sometimes, you see extremely high %Disk Times and think that your subsystem is bottlenecked. However, you want to examine other overview counters before going in one direction. For example, when available memory drops to critical levels, NT will begin to page or write unused data or code to the hard drive to make room for more active programs. With extreme resource starvation, your disk subsystem can be reading and writing furiously and appear to be bottlenecked. Looking at other general disk counters in Perfmon will validate this illusion.
However, when you examine both memory and disk subsystem counters, you'll notice that during prolonged memory paging, disk activity increases.
The solution is to add more memory, not increase your disk subsystem capacity.
![]()
The following sections will provide you with some information to help to detect hard disk bottlenecks and some tips on how to improve disk efficiency on your Exchange servers.
Physical Disk: % Disk Time
Disk Time is the percentage of elapsed time that the selected disk drive is busy servicing read or write requests. In other words, this counter provides an indication of how busy your disk subsystem is over the time period you're measuring in Perfmon. A consistent average over 95% indicates significant disk activity.
Physical Disk: Disk Queue Length
This counter measures the number of requests that are waiting to use disk subsystem. This counter should average less than 2% for good performance. Use the Disk Queue Length counter combined with the % Disk Time counter, to give you an exceptional overview of your disk subsystem's workload.
Both counters can monitor either your server's physically installed disks spindles or RAID bundles.
Inproving Disk Access Efficiency
The public and private information stores both utilize a transaction log that is written sequentially to disk. If possible, place the logs into separate physical spindles, preferably with the private store on the fastest drive.
You can separate Windows NT processes (paging file, event viewer log, Dr. Watson logs), and Exchange processes (message tracking logs, Microsoft Mail connection post office, directory database, Internet Mail connector logs) to enhance performance. You can also separate the public and private information stores transaction logs to separate disks or arrays for even more performance.
Overall, if you have a RAID subsystem, installing more drives yields faster throughput.
Choose a disk with a low seek time, which means the time required to move the disk drive's heads from one track of data to another. The ratio of time spent seeking as opposed to time spent transferring data is usually 10 to 1.
Determine whether the controller card does 8-bit, 16-bit, or 32-bit transfers. The more bits in the transfer operation, the faster the controller moves data.
Use RAID 0 (disk striping) to increase overall capacity for random reads and writes. You will need at least two physical drives for RAID 0. Use RAID 5 (disk striping with parity) for slightly less performance, but more fault tolerance. You will need at least three physical drives for RAID 5.
If you implement RAID at the hardware level, choose a controller card with a large (4 megabytes) on-board cache.
When Exchange runs, it only keeps portions of data needed, referred to as pages, in memory at any one time. When it needs a page of data that is not in RAM (page fault), NT will load that page into physical memory from a peripheral, which is usually the hard drive. The average instruction in memory executes in nanoseconds, which is one-billionth of a second, and hard drive seek and access times are in milliseconds. Therefore, NT must run 100,000 times slower than normal to retrieve a page from disk.
Keep in mind that Exchange needs a minimum of 32MB of RAM.
How to Detect Memory Bottlenecks
The following sections will assist you in detecting detrimental system performace caused by improper use of Random Access Memory. Also, you will learn some techniques to better handle memory usage on your Exchange servers.
Overview counter - Memory: Pages/sec
Pages/sec reports the number of pages read or written to a disk to resolve page faults. You can turn this on when your system is under a typical load. If this counter averages above 5, a memory bottleneck is starting to form, and your disk subsystem is beginning to take a beating.
You will want to add more memory until paging stops or occurs minimally. Afterwards, be sure to run Performance Optimizer to adjust Exchange's memory caches.
If your disk subsystem supports concurrent I/O requests, using multiple paging files usually improves system performance. Be sure to place the paging file on your fastest hard drive, and experiment with separating NT's paging file from Exchange's transaction log files.
Remove Unnecessary Services
Disable any unneeded services, protocols, and device drivers. Even idle components consume some memory and contribute to general system overhead.
The next section will discuss performance issues related to your network infrastructure.
A network by its heterogenous nature is full of potential performance bottlenecks. A company full of servers and clients talking in different protocols can often cause poor performance with Exchange. The following sections will help you to detect poor network performance with Exchange and help you improve it.
When a network bottleneck forms, one the following three scenarios can result:
The following counters are available to clients running NT:
NWLink: Bytes Total/sec (IPX/SPX)
Network Interface: Bytes Total/sec (TCP/IP)
NetBEUI: Bytes Total/sec
If you want to measure a client's workload, use the appropriate counter for your protocol. When your overview counters are generally idle, but your network counters are high, you can usually infer that your network has a bottleneck on the client end. This means that your client is doing most of its work gabbing with the network.
This counter also gives you an indication of how much load this client is placing on the network.
Redirector: Network Errors/sec
This counts serious network errors between the redirector and one or more servers. It applies to any protocol running on the client station, and shows if you have a network corruption problem. Each error is logged in detail in NT's Event Log.
This counter should normally be zero.
Server: Bytes Total/sec
This counter measures most of the meaningful server activity, and provides an insight into the server's load. It also provides an insight into how much load this server is contributing to the network's overall load.
Server: Sessions Errored Out
This counter measures the number of client sessions that are closed due to unexpected network errors. If this counter rises on one server, you might have a faulty network card. If the counter increases on several servers, check into the LAN infrastructure itself, such as routers, hubs, bridges, physical cabling or connections, to determine whether you have a more serious network corruption issue.
This counter should normally be zero.
![]()
All of the following Exchange counters are available in Perfmon after you have installed Exchange.
![]()
MSExchangeMTA: Messages/sec
Messages/sec monitors the number of messages the MTA sends and receives every second. In other words, it measures the traffic generated by message flow. This is a quick way to focus on message traffic sent to other servers. For more specific information on message traffic, refer to the message tracking logs.
MSExchangeMTA: Messages Bytes/sec
Similar to the preceding counter, this counts the sums of the number of bytes in each message the MTA sends and receives each second. In other words, it reports the amount of message traffic measured in bytes.
MSExchangeISPublic: Rate of Open Message operations
This counter measures the rate at which messages are opened in the public folder. Overall, it measures public folder use. You can use this to determine whether public folder activity is balanced among servers.
MSExchangeDS: Reads/sec
This counter measures the amount of traffic generated by directory synchronizations.
![]()
You might be wondering what is a good figure for Server: Bytes Total/sec or for MSExchangeMTA: Messages/sec. The truth is that there is no simple answer. The reason is that your network has far too many variables.
Next, you might be wondering what are the maximum values. Again, there are no simple answers. For example, how could you find the maximum speed of your car? You can probably discover this by driving as fast as possible. But notice all the variables that will affect your maximum speed. Do you test drive the car up or down a hill, at sea level or at 10,000 feet? Whether you test drive on a cold or a hot day will affect the result. For example, cold air is denser and provides a performance boost, especially for turbo and supercharged engines.
The best approach is to drive your system through many conditions until you get a feel for its normal ranges or personality. To assist you in this process, you can use Loadsim which creates a synthetic load of hundreds of users on your system. While running your simulation, crank up Perfmon to monitor the load and get a feel for your server's personality.
![]()
The following sections include suggestions that will improve network performance among your Exchange servers.
For the most leverage, you should apply hardware upgrades to machines generating the most traffic, as well as servers on the heaviest traffic links. This will provide a system-wide balance for your Exchange environment.
You can use a combination of the counters mentioned in the previous sections to determine which machine is generating traffic. A product such as Microsoft SMS can determine which network links experience the greatest load.
If the Server: Bytes Total/sec or corresponding client counter begins to reach the maximum bandwidth of the network link to which your server is connected, you should consider segmenting your network. On an ethernet segment, this value is approximately 1.2 megabits per second, once you include the overhead of the network.
If your client or server has a 32-bit bus, use a 32-bit adapter card. Overall, you should use the fastest network card and matching bus available.
If you determine your network is overloaded, increase its bandwidth by upgrading to faster network link technology, for example, Fast Ethernet, FDDI, or ATM.
Exchange is tightly integrated with NT. Therefore, it can take full advantage of a more advanced processor or multiple processors. You should eliminate all other bottlenecks before investigating the processor.
Processor: % Processor Time or System: % Total Processor Time
Either one of these counters will determine whether your CPU is overloaded. These counters measure the total time your system is executing programs (non-idle threads). If either counter averages over 95%, your CPU is probably eperiencing a bottleneck. The System counter is useful for multiprocessor systems. The reason is that it averages the processor use for all installed processors.
You can upgrade to the fastest processor available. If this has been done, add additional processors if your hardware supports symmetrical multiprocessing. Keep in mind that NT Supports MIPS and Alpha, as well as Intel processors.
Overall, the addition of another CPU will typically give a better performance increase than upgrading to a faster single processor. The reason is that the multithreaded design of all Microsoft BackOffice products enables superior performance in a multiple prcessor environment.
You might also consider scheduling processor intensive activities to off peak hours.
Using Loadsim
Loadsim can help you measure the response time using an artificially generated server load. Loadsim can also measure "acceptability" by weighting certain actions that are perceived as more important by the user.
Loadsim measures two items with respect to an Exchange server: response time and "acceptability". To measure response time, Loadsim uses the 95th percentile. If the 95th percentile for a set of actions is one second, 95 percent of the response times are at or below one second. Only five percent (one in twenty) of the response times exceeded one second. To compare, the maximum response time is the 100th percentile. In other words, 100 percent of the response times are at or below the maximum.
To measure acceptability, Loadsim places a heavier weight on simulated actions that are perceived as more important to a real user. For example, most users expect quick responses when opening or deleting messages. They aren't, however, as affected by a small delay when sending mail. The actual actions and weights are categorized below.
Table 22.1
Loadsim Can Give You Weight Values.
| Action | Weight |
| Read | 10 |
| Delete | 2 |
| Send | 1 |
| Reply | 1 |
| Reply All | 1 |
| Forward | 1 |
| Move | 1 |
![]()
LsLog is a Loadsim tool that enables you to change the default percentile (95) and the weighted values for any action. For more information, refer to the Loadsim documentation and on-line help.
![]()
To arrive at the final number, Loadsim multiplies each percentile value by the corresponding weight. Then, Loadsim adds the results, and divides by the sum of all weights. This final number is referred to as the score, and represents the response time experienced by a simulated user.
The following list includes client requirements and recommendations that might make your Loadsim experience more productive:
It is possible to monitor Loadsim's actions with the Performance Monitor to determine which resource will be bottlenecked first as the number of users rises. This is especially useful for capacity planning.
You should also use Perfmon to separate client—side influences from the server side. Loadsim is executed from a client desktop. You should, therefore, use Perfmon before Loadsim to tune all major bottlenecks. Then, while Loadsim is running, use Perfmon to determine whether a client—side bottleneck is skewing your data.
This test was run on a server with a Pentium 90 MHz CPU, 64MB of RAM, a 32-bit network card with bus mastering, and a 32-bit controller card with 4MB of on-board cache memory managing two 4.2 gig hard drives. This server was optimized by the Performance Optimizer and Performance Monitor before running the Loadsim test.
The following table lists the values for various Loadsim parameters. These values were used to configure Loadsim before executing the simulation.
Table 22.2
"These values are for various Loadsim simulation parameters
| Initialize Users Parameters | Value |
| Number of Non-Default Folders | 40 |
| Number of Messages per Folder | 5 |
| Number of Messages in the Inbox | 4 |
| Number of Messages in Deleted Items | 1 |
Table 22.3
These values represent user task parameters
| User Task Parameters | Value |
| Hours in Day | 8 |
| Originate New Mail (not Reply or Forward) Text only message | 4x |
| 1k text message | 60 |
| 2k text message | 16 |
| 4k text message | 4 |
| 1k text message with attachment | |
| 10k attachment | 5 |
| Excel attachment | 4 |
| Word attachment | 2 |
| Embedded bitmap | 2 |
| Embedded Excel Object | 2 |
| Recipients per New or Forward Message | 3 |
| Add Distribution List to Addressees | 30% |
| Read New Mail | 12x |
| Send Reply | 7% |
| Send Reply All | 5% |
| Send Forward | 7% |
| Delete (move to Deleted Items Folder) | 40% |
| Move Messages | 20% |
| Load Attachments on Read Mail | 25% |
| Maximum In box size in Messages | 125 |
| Other old mail processing | 15x |
| Schedule + Changes | 5x |
| Empty Delete Items Folder | 1x |
| Messages sent per 8 hour day(computed average) | 13.5 |
| Messages received per 8 hour day(computed average) | 68.8 |
![]()
Each simulated user executes one task at a time.
Each simulated user performs each task at randomly spaced intervals throughout each simulated day.
All tasks are completed within each simulated day.
![]()
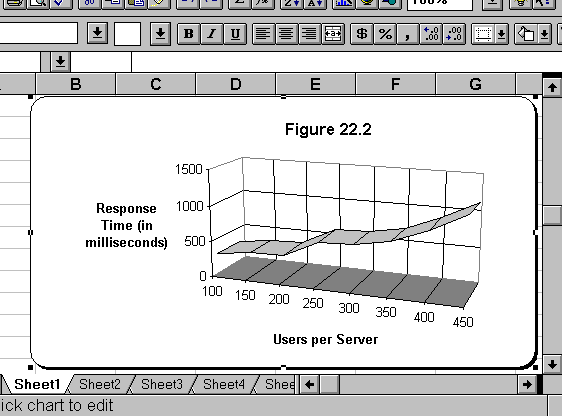
Figure 22.2 illustrates Loadsim's results. The two important numbers are a response time of 1000 ms and 430 users per server. This is the crossover point at which response time becomes unacceptable.
Therefore, this server can support 430 users with a response time of one second or less occurring 95 percent of the time.
This chart represents Loadsim's results
From Here...
You now know which components to measure, and how to use optimization tools. You also know the answer to the question, "How many users can Exchange support?"
This knowledge will enable you to solve the largest performance problems within your organization.
This chapter has addressed the topic of performance tuning and capacity planning. For more information, refer to the following chapters:
For technical support for our books and software contact support@mcp.com
Copyright ©1996, Que Corporation
{kind=link}