![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Cosa è una biblioteca digitaleLe prime pionieristiche sperimentazioni nel campo delle biblioteche digitali, come vedremo, sono quasi coeve alla nascita di Internet. Ma è soprattutto dall'inizio di questo decennio che si è assistito ad una notevole crescita delle sperimentazioni e dei progetti, alcuni dei quali finanziati da grandi enti pubblici in vari paesi. Parallelamente alla proliferazione di iniziative, si è avuta una crescente attenzione teorica e metodologica al tema delle biblioteche digitali, tanto da giustificare la sedimentazione di un dominio disciplinare autonomo. Alla costituzione di questo dominio hanno fornito importanti contributi vari settori della ricerca informatica e sui nuovi media, come l'area del text processing, dell'information retrieval e degli agenti software, della grafica computerizzata, della telematica e delle reti computer. Ma senza dubbio i contributi di maggiore rilievo sono venuti dalle ricerche sui sistemi informativi distribuiti e dalla teoria degli ipertesti, nel cui contesto si può rintracciare la genealogia stessa dell'idea di 'biblioteca digitale'. I primi spunti in questo campo precedono la nascita di Internet e persino lo sviluppo dei computer digitali. Ci riferiamo al classico articolo di Vannevar Bush How we may think dove il tecnologo americano immagina l'ormai celeberrimo Memex. Si trattava di una sorta di scrivania automatizzata, dotata di un sistema di proiezione di microfilm e di una serie di apparati che consentivano di collegare tra loro i documenti su di essi fotografati. Lo stesso Bush, introducendo la descrizione del suo ingegnoso sistema di ricerca e consultazione di documenti interrelati, lo definì una "sorta di archivio e biblioteca privati" [54]. Una approssimazione maggiore all'idea di biblioteca digitale (sebbene il termine non compaia esplicitamente), si ritrova nel concetto di docuverso elaborato da Ted Nelson, cui dobbiamo anche la prima formulazione esplicita dell'idea di ipertesto digitale [55]. Nelson, sin dai suoi primi scritti degli anni 60, descrive un sistema ipertestuale distribuito (che poi battezzerà Xanadu) costituito da una rete di documenti e dotato di un sistema di indirizzamento e di reperimento. La convergenza teorica e tecnica tra biblioteche digitali e sistemi ipertestuali distribuiti trova infine pieno compimento con la nascita e lo sviluppo di World Wide Web. L'ambiente ipertestuale della rete Internet, infatti, ha fornito un ambiente ideale per la sperimentazione concreta e diffusa di tutta l'elaborazione teorica accumulata in questo settore negli anni passati. Tuttavia, se la teoria degli ipertesti distribuiti rappresenta un punto di riferimento centrale nella discussione relativa alla struttura e alle funzioni di una biblioteca digitale, essa non consente di distinguere con sufficiente chiarezza tra l'idea generica di un sistema di pubblicazione on-line di documenti digitali, l'idea di ipertesto distribuito e una nozione più formale e rigorosa di biblioteca digitale [56]. Se il termine 'biblioteca digitale' individua un'area specifica di applicazione, occorre precisare in che senso la determinazione di 'digitale' si applica alla nozione di biblioteca; in che modo una biblioteca digitale si differenza da una tradizionale e in che modo invece ne eredita funzioni e caratteristiche; come, infine, sia possibile distinguerla da altri sistemi informativi distribuiti (come appunto il Web in generale). A tale fine possiamo distinguere tra la nozione astratta di 'biblioteca digitale' e la nozione funzionale e applicativa di 'sistema di biblioteca digitale'. La nozione astratta di biblioteca digitale concerne la rappresentazione digitale del contenuto informativo di una biblioteca e delle metainformazioni (o metadati) atte al reperimento di specifiche sezioni al suo interno. Tale contenuto ha la forma di un insieme di documenti dotato di un'organizzazione complessiva dovuta ad un agente intenzionale distinto dai creatori dei singoli documenti in essa contenuti. La nozione di 'sistema di biblioteca digitale', invece, attiene alle risorse tecnologiche (risorse hardware, sistemi di rete, software di stoccaggio dei dati, interfacce utente e sistemi di information retrieval) necessarie ad implementare tale modello, e di conseguenze individua le funzioni e i servizi che vengono messi a disposizione degli utenti. Alla luce di queste riflessioni definiamo 'biblioteca digitale' una collezione di documenti digitali strutturati (sia prodotti mediante digitalizzazione di originali materiali, sia realizzati ex-novo), dotata di un'organizzazione complessiva coerente di natura semantica e tematica, che si manifesta mediante un insieme di relazioni interdocumentali e intradocumentali e mediante un adeguato apparato metainformativo. In questo senso possiamo distinguere una biblioteca digitale da un insieme non organizzato di informazioni assolutamente eterogenee come World Wide Web, ma anche da molti archivi testuali che attualmente sono disponibili su Internet e che si presentano come 'depositi testuali' piuttosto che come vere e proprie biblioteche. Le varie tipologie di biblioteche digitali su InternetInternet ormai ospita un ingente numero di banche dati testuali, di varia tipologia. Gran parte di queste esperienze sono ancora lontane dall'incarnare esattamente la definizione di biblioteca digitale che abbiamo proposto nel paragrafo precedente. Ma allo stesso tempo esse dimostrano l'enorme potenzialità della rete come strumento di diffusione dell'informazione e come laboratorio di un nuovo spazio comunicativo, lasciando prefigurare una nuova forma nella diffusione e fruizione del sapere. D'altra parte qualsiasi definizione teorica rappresenta una sorta di ipostatizzazione ideale e astratta di fenomeni reali che presentano sempre idiosincrasie e caratteri particolari. E questo è tanto più vero in un mondo proteico e in continua evoluzione come quello della rete Internet. Nell'ambito di questa vasta e variegata congerie di progetti e sperimentazioni è tuttavia possibile individuare alcuni tratti distintivi che ci consentono di tracciare una provvisoria tassonomia. Il primo criterio in base al quale possono essere suddivise le attuali biblioteche digitali su Internet è relativo ai formati con cui i documenti vengono archiviati alla fonte e distribuiti agli utenti (formati, si noti, non necessariamente coincidenti). Se si analizza lo spettro dei formati di codifica correntemente adottati nelle sperimentazioni di biblioteche digitali, si riscontrano le seguenti tipologie:
Si deve rilevare come la presenza di schemi proprietari dimostri la scarsa attenzione dedicata al problema della preservazione, mentre l'adozione di codifiche 'puro testo' o HTML denoti altrettanta negligenza riguardo agli aspetti qualitativi e categoriali implicati dalla rappresentazione digitale dei documenti. Il problema della preservazione a lungo termine del patrimonio documentale è di capitale importanza per lo sviluppo delle biblioteche digitali. Se la preservazione in una biblioteca convenzionale riguarda la conservazione di oggetti materiali deperibili (libri, periodici, incunaboli, manoscritti documenti d'archivio etc.) ed eventualmente il loro restauro, nella biblioteca digitale esso si articola su tre livelli: livello hardware, livello software e livello dei sistemi di codifica dei documenti. Come è noto, la curva di invecchiamento delle tecnologie informatiche è assai rapida, e impone il periodico aggiornamento di qualsiasi sistema informativo. Tuttavia, tale aggiornamento rende progressivamente inaccessibili le risorse informative generate mediante gli strumenti tecnologici divenuti obsoleti. Questo può portare ad una situazione in apparenza paradossale. I libri a stampa hanno tranquillamente superato i cinquecento anni di vita mantenendo pressoché intatta la loro disponibilità alla lettura, e alcuni manoscritti risalgono ad oltre duemila anni fa. Un documento elettronico, che sembra godere della massima 'riproducibilità tecnica', rischia di divenire inutilizzabile nel giro di pochissimi anni. La preservazione a lungo termine dei documenti digitali, pertanto, richiede l'adozione di sistemi di rappresentazione e archiviazione informatica dell'informazione standardizzati e tecnicamente portabili. Naturalmente, affinché uno standard di rappresentazione dell'informazione sia effettivamente portabile deve essere dotato di alcune caratteristiche tecniche e informatiche:
Allo stato attuale, la tecnologia che meglio risponde a tutte le esigenze che abbiamo enunciato è senza dubbio lo Standard Generalized Markup Language, e i formati ad esso correlati. In effetti, tutti i progetti di banche dati testuali più avanzati (sia in ambito accademico sia bibliotecario) attualmente presenti su Internet sono orientati in questo senso. In particolare, nel mondo della ricerca umanistica ha assunto un notevole rilievo la Text Encoding Initiative, una vasta e complessa applicazione SGML progettata specificamente per la codifica di testi letterari e documenti storici e linguistici. Un limite alla diffusione di SGML è costituito dalla sua complessità e, problema non secondario, dagli ingenti costi di implementazione. Per questo, riveste un ruolo molto importante la recente formalizzazione di un sottoinsieme semplificato di SGML da parte del World Wide Web Consortium, denominato Extensible Markup Language (XML) [58]. Un secondo aspetto in base al quale possono essere suddivise le biblioteche digitali in rete riguarda le modalità di accesso e di consultazione dei documenti elettronici in esse contenuti. In generale possiamo distinguere tre modalità con cui un utente può accedere ai documenti archiviati in una biblioteca digitale:
Naturalmente ognuna di queste modalità non esclude le altre. Tuttavia sono molto poche le biblioteche digitali attualmente esistenti che offrono tutti e tre i servizi. In genere sono molto diffusi i primi due tipi di accesso, mentre i servizi di ricerca e analisi dei documenti sono disponibili solo in alcuni sistemi sviluppati in ambito bibliotecario o accademico. Si tratta di servizi che adottano software di archiviazione molto avanzati, spesso basati su tecnologie SGML, che permettono agli utenti di effettuare raffinate ricerche contestuali. Un ultimo criterio distintivo per le biblioteche digitali su Internet, infine, riguarda il tipo di ente, organizzazione o struttura che ha realizzato la biblioteca, e ne cura la manutenzione. Da questo punto di vista possiamo ripartire i progetti attualmente in corso in tre classi:
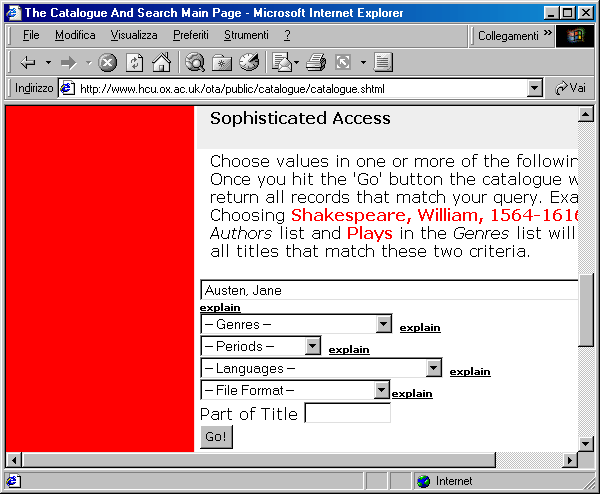
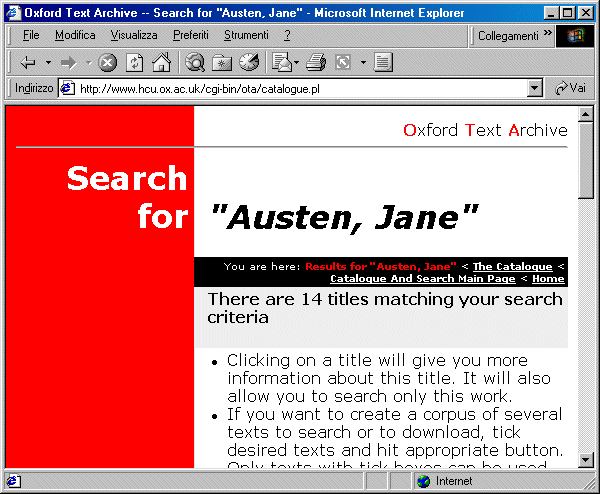
Il primo gruppo è costituito da una serie di sperimentazioni avviate dalle grandi biblioteche nazionali o da consorzi bibliotecari, con forti finanziamenti pubblici o, per quanto attiene al nostro continente, comunitari. Il secondo gruppo è costituito da sperimentazioni e servizi realizzati in ambito accademico. Si tratta in genere di progetti di ricerca specializzati, che possono disporre di strumenti tecnologici e di competenze specifiche molto qualificate, a garanzia della qualità scientifica delle edizioni digitalizzate. Tuttavia non sempre i materiali archiviati sono liberamente disponibili all'utenza esterna. Infatti vi si trovano assai spesso documenti coperti da diritti di autore. Su questo punto ci concediamo una breve digressione. Il tema del copyright, infatti, è fondamentale per lo sviluppo delle biblioteche digitali nel prossimo futuro. Le attuali legislazioni, modellate sulla tecnologia della stampa, sono state estese per analogia alla distribuzione telematica. Tuttavia, in un nuovo mezzo di comunicazione in cui la riproduzione delle risorse è alla portata di chiunque e non costa nulla, questa estensione rischia di imporre dei vincoli troppo rigidi, e di avere un effetto di freno allo sviluppo. D'altra parte non si può dimenticare che i diritti intellettuali sono la fonte di sostentamento degli autori. Meno giustificata la durata dei diritti, attualmente fissata a settanta anni dalla morte dell'autore, che tutela piuttosto le case editrici. Una soluzione di carattere 'libertario' potrebbe consistere nella diminuzione della durata dei diritti, eventualmente limitata alla distribuzione telematica senza scopo di lucro e per finalità scientifiche e culturali (il cosiddetto fair use). In alternativa si potrebbe studiare un meccanismo di micropagamenti che verrebbero addebitati all'utente nel momento in cui accede ad un documento (il sistema pay per view). In tale direzione sono in corso molti studi e progetti, ma per il momento nessuna tecnologia di questo tipo è effettivamente operativa. Accanto alle biblioteche digitali realizzate da soggetti istituzionali, si collocano una serie di progetti, sviluppati e curati da organizzazioni e associazioni private di natura volontaria. Queste banche dati contengono testi che l'utente può prelevare liberamente e poi utilizzare sulla propria stazione di lavoro; chiaramente tutti i testi sono liberi da diritti d'autore. Le edizioni elettroniche contenute in questi archivi non hanno sempre un grado di affidabilità filologica elevato. Tuttavia si tratta di iniziative che, basandosi sullo sforzo volontario di moltissime persone, possono avere buoni ritmi di crescita, e che già oggi mettono a disposizione di un vasto numero di utenti una notevole mole di materiale altrimenti inaccessibile. I repertori di biblioteche digitali e archivi testualiIl numero di biblioteche digitali presenti su Internet è oggi assai consistente, e nuove iniziative vedono la luce ogni mese. Nella maggior parte dei casi questi archivi contengono testi letterari o saggistici in lingua inglese, ma non mancano archivi di testi in molte altre lingue occidentali, archivi di testi latini e greci, e biblioteche speciali con fondi dedicati a particolari autori o temi. Nei prossimi paragrafi ci occuperemo di alcune iniziative che ci sembrano a vario titolo esemplari. Per un quadro generale ed esaustivo, invece, invitiamo il lettore a consultare i vari repertori di documenti elettronici e biblioteche digitali disponibili in rete. Esistono due tipi di meta-risorse dedicate ai testi elettronici: repertori di progetti nel campo delle biblioteche digitali e meta-cataloghi di testi elettronici disponibili su Internet. Tra i primi ricordiamo il Digital Initiative Database (http://www.arl.org/did) realizzato dalla Association of Research Libraries (ARL). Si tratta di un database che contiene notizie relative ad iniziative di digitalizzazione di materiali documentali di varia natura in corso presso biblioteche o istituzioni accademiche e di ricerca. Le ricerche possono essere effettuate per nome del progetto o per istituzione responsabile dello stesso, ma si può anche scorrere il contenuto dell'intero database. Per i progetti di biblioteche digitali sviluppati in ambito accademico molto utile è la Directory of Electronic Text Centers compilata da Mary Mallery (http://scc01.rutgers.edu/ceth/infosrv/ectrdir.html) del Center for Electronic Texts in the Humanities (CETH). Si tratta di un inventario ragionato di archivi testuali suddiviso per enti di appartenenza. Per ognuno dei centri elencati, oltre ad un link diretto, vengono forniti gli estremi dei responsabili scientifici, l'indirizzo dell'ente, e una breve descrizione delle risorse contenute. Anche la Text Encoding Initiative, sul suo sito Web, ha realizzato un elenco dei vari progetti di ricerca e archivi testuali basati sulle sue fondamentali norme di codifica. La 'Application List' (il cui indirizzo Web esatto è http://www-tei.uic.edu/orgs/tei/app) fornisce informazioni e link diretti alle home page di più di cinquanta iniziative, tra le quali si annoverano alcune tra le più interessanti e avanzate esperienze di biblioteche digitali attualmente in corso. Un'altra importante fonte di informazione circa le applicazioni delle tecnologie SGML in ambito scientifico, è costituita dalla sezione 'Academic Projects and Applications' della SGML/XML Web Page curata da Robin Cover (http://www.oasis-open.org/cover/acadapps.html). Molto ricco di informazioni relative al tema delle biblioteche digitali è il Berkeley Digital Library SunSITE (http://sunsite.berkeley.edu). Si tratta di un progetto realizzato dalla University of Berkeley volto a favorire progetti di ricerca nel campo delle biblioteche digitali attraverso la fornitura di supporto tecnico e logistico. Nell'ambito di questa iniziativa sono state avviate un serie di sperimentazioni che vedono coinvolte numerose università, biblioteche e centri di ricerca nordamericani in vari ambiti disciplinari. Il sito, oltre ad avere un archivio delle iniziative in cui è direttamente coinvolto, fornisce anche un repertorio generale di biblioteche digitali all'indirizzo http://sunsite.berkeley.edu/Collections/othertext.html. A differenza dei repertori di biblioteche digitali, i meta-cataloghi di testi elettronici forniscono dei veri e propri indici ricercabili di documenti, indipendentemente dalla loro collocazione originaria. Due sono le risorse di questo tipo che occorre menzionare. La prima è The On-Line Books Page, realizzata da Mark Ockerbloom e ospitata dalla Carnegie Mellon University (http://www.cs.cmu.edu/books.html). Questo sito offre un catalogo automatizzato di opere in lingua inglese disponibili gratuitamente in rete, contenente circa 9.000 entrate. La ricerca può essere effettuata per autore, titolo e soggetto, e fornisce come risultato un elenco di puntatori agli indirizzi originali dei documenti individuati. Oltre al catalogo, il sito contiene (nella sezione intitolata 'Archives') anche un ottimo repertorio di biblioteche e archivi digitali e di progetti settoriali di editoria elettronica presenti su Internet. La seconda è l'Alex Catalogue of Electronic Texts, curato da Eric Lease Morgan e ospitato sul sito di Berkeley (http://sunsite.berkeley.edu/alex). Alex è nato molti anni fa come gopher e, dopo un parentesi durante la quale è stato abbandonato per mancanza di fondi, è stato completamente ridisegnato come servizio Web. In questa nuova forma si è trasformato da un semplice catalogo in un vero e proprio archivio indipendente di testi elettronici, dotato di servizi di ricerca bibliografica e di analisi testuale. La ricerca nel catalogo può essere effettuata attraverso le chiavi 'autore' e titolo'. Una volta individuato il documento ricercato, è possibile visualizzarne il testo nella copia locale, risalire a quella originale, oppure effettuare ricerche per parola al suo interno o nelle sue concordanze. Un servizio aggiuntivo offerto da Alex è la generazione automatica di versioni PDF ed ebook (da utilizzare con alcuni palm computer come Newton e PalmPilot), che possono essere lette più comodamente off-line. I grandi progetti bibliotecariCome abbiamo detto, l'interesse del mondo bibliotecario tradizionale verso il problema della digitalizzazione è andato crescendo negli ultimi anni. La diffusione della rete Internet, e in generale la diffusione delle nuove tecnologie di comunicazione e di archiviazione dell'informazione, comincia a porre all'ordine del giorno il problema della 'migrazione' dell'intero patrimonio culturale dell'umanità su supporto digitale. Consapevoli dell'importanza di questa transizione, alcune grandi istituzioni hanno dato vita a grandiosi progetti di digitalizzazione. Per limitarci all iniziative di maggiore momento, ricordiamo in ambito statunitense la Digital Libraries Initiative (DLI, http://dli.grainger.uiuc.edu/national.htm). Si tratta di un importante programma nazionale di ricerca finanziato congiuntamente dalla National Science Foundation (NSF), dalla Department of Defense Advanced Research Projects Agency (DARPA) e dalla NASA. Scopo dell'iniziativa è lo sviluppo di tecnologie avanzate per raccogliere, archiviare e organizzare l'informazione in formato digitale, e renderla disponibile per la ricerca, il recupero e l'elaborazione attraverso le reti di comunicazione. Vi partecipano sei università, che hanno avviato altrettanti progetti sperimentali concernenti la creazione di biblioteche digitali multimediali distribuite su rete geografica, l'analisi dei modelli di archiviazione e conservazione delle risorse documentali, e la sperimentazioni di sistemi di interfaccia per l'utenza. Le collezioni oggetto di sperimentazione sono costituite da testi, immagini, mappe, registrazioni audio, video e spezzoni di film. Proprio nel corso del 1999 il programma DLI è stato rinnovato, portando all'aumento dei progetti in previsione di finanziamento. Legata alla DLI è la rivista telematica D-lib Magazine, sponsorizzata dalla DARPA, un interessante osservatorio sugli sviluppi in corso nel settore delle biblioteche digitali. Con periodicità mensile, D-Lib ospita articoli teorici e tecnici, e aggiorna circa l'andamento dei progetti di ricerca in corso. Il sito Web, il cui indirizzo è http://www.dlib.org, contiene, oltre all'ultimo numero uscito, anche l'archivio di tutti i numeri precedenti, e una serie di riferimenti a siti e documenti sul tema delle biblioteche digitali. Un programma in parte simile è stato avviato in ambito britannico. Si tratta del progetto eLib (si veda il sito Web http://www.ukoln.ac.uk/services/elib) che, pur avendo una portata più generale (riguarda infatti tutti gli aspetti dell'automazione in campo bibliotecario), ha finanziato varie iniziative rientranti nell'ambito delle biblioteche digitali, tra cui la Internet Library of Early Journals, un archivio digitale di giornali del XVIII e XIX secolo realizzato dalle Università di Birmingham, Leeds, Manchester e Oxford (http://www.bodley.ox.ac.uk/ilej). Diversi progetti sono stati sostenuti anche dall'Unione Europea, nel contesto dei vari programmi di finanziamento relativi all'automazione bibliotecaria, e in particolare dalla DG XIII che ha dato vita ad un programma intitolato Digital Heritage and Cultural Content (http://www.echo.lu/digicult). Dal canto loro, anche alcune grandi biblioteche nazionali si sono attivate in questo senso. Probabilmente l'iniziativa più nota è quella dalla Bibliothèque Nationale de France, che ha avviato un progetto per l'archiviazione elettronica del suo patrimonio librario sin dal 1992. Obiettivo del progetto è la digitalizzazione di centomila testi e trecentomila immagini, che saranno consultabili sia tramite Internet sia mediante apposite stazioni di lavoro collocate nel nuovo edificio della biblioteca a Parigi. Un primo risultato sperimentale di questo grandioso progetto è il sito Gallica (http://gallica.bnf.fr/), dedicato alla cultura francese del 1800. Si tratta di una banca dati costituita da 2.500 opere digitalizzate in formato immagine, 250 opere memorizzate in formato testo e una vasta rassegna iconografica del periodo. Attraverso un motore di ricerca è possibile consultare il catalogo e poi accedere ai documenti, che vengono distribuiti in formato PDF (è dunque necessario installare il plug-in Adobe Acrobat Reader). Un progetto simile è stato intrapreso dalla Library of Congress di Washington, che peraltro partecipa attivamente al programma DLI. Il primo risultato dei programmi di digitalizzazione della LC è il già citato progetto American Memory (http://memory.oc.gov). Si tratta di un archivio di documenti storici, testi, lettere e memorie private, foto, immagini, filmati relativi alla storia del paese dalle sue origini ai giorni nostri. Tutti i documenti, parte dell'enorme patrimonio documentalistico della biblioteca, sono stati digitalizzati in formato SGML per i materiali testuali, JPEG e MPEG per immagini e filmati, e inseriti in un grande archivio multimediale che può essere ricercato secondo vari criteri. Anche la Biblioteca Vaticana, in collaborazione con la IBM, ha avviato un progetto sperimentale per distribuire le immagini digitalizzate del suo inestimabile patrimonio di manoscritti. Da poco è stata conclusa la prima fase, che ha riguardato circa cento manoscritti, ora a disposizione di un selezionato e purtroppo ristretto gruppo di studiosi in tutto il mondo. Le biblioteche digitali in ambito accademicoAccanto ai grandi progetti nazionali e bibliotecari, si colloca una mole ormai ingente di sperimentazioni che nascono in ambito accademico (in particolare nell'area umanistica) e sono gestite da biblioteche universitarie o da centri di ricerca costituiti ad hoc. I fondi documentali realizzati attraverso questa serie di iniziative rispondono a criteri (tematici, temporali, di genere, etc.) ben definiti e si configurano come l'equivalente digitale delle biblioteche speciali e di ricerca. Oxford Text ArchiveTra i progetti sviluppati presso sedi universitarie e centri di ricerca istituzionali, quello che spicca per prestigio, autorevolezza e tradizione (se di tradizione si può parlare in questo campo) è l'Oxford Text Archive (OTA), realizzato dall'Oxford University Computing Services (OUCS). L'archivio è costituito (nel momento in cui scriviamo) da oltre 2500 testi elettronici di ambito letterario e saggistico, oltre che da alcune opere di riferimento standard per la lingua inglese (ad esempio il British National Corpus, e il Roget Thesaurus). La maggior parte dei titoli sono collocati nell'area culturale anglosassone, ma non mancano testi latini, greci e in altre lingue nazionali (tra cui l'italiano). Gran parte delle risorse dell'OTA provengono da singoli studiosi e centri di ricerca di tutto il mondo che forniscono a questa importante istituzione le trascrizioni e le edizioni elettroniche effettuate nella loro attività scientifica. Per questo l'archivio è costituito da edizioni altamente qualificate dal punto di vista filologico, che rappresentano una importante risorsa di carattere scientifico, specialmente per la comunità umanistica. I testi sono per la maggior parte codificati in formato SGML, in base alle specifiche TEI. Poiché in molti casi si tratta di opere coperte da diritti di autore, solo una parte dei testi posseduti dall'OTA sono accessibili gratuitamente su Internet. Degli altri, alcuni possono essere ordinati tramite posta normale, fax o e-mail (informazioni e modulo di richiesta sono sul sito Web dell'archivio); i restanti, possono essere consultati e utilizzati presso il centro informatico di Oxford, a cui tuttavia hanno accesso esclusivamente ricercatori e studiosi. L'accesso alla collezione pubblica dell'OTA si basa su una interfaccia Web particolarmente curata e dotata di interessanti servizi (http://ota.ahds.ac.uk). In primo luogo è disponibile un catalogo elettronico dei testi che può essere ricercato per autore, genere, lingua, formato e titolo.
Una volta individuati i documenti desiderati, l'utente può decidere di effettuare il download dei file selezionati o di accedere ad una maschera di ricerca per termini che genera un elenco di concordanze in format Key Word In Context (KWIC, in cui il termine ricercato viene mostrato nell'ambito di un contesto variabile di parole che lo precedono e lo seguono), da cui poi è possibile accedere all'intero documento.
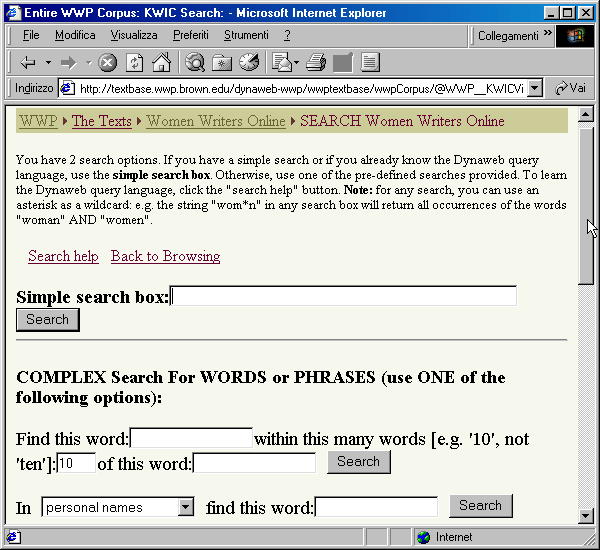
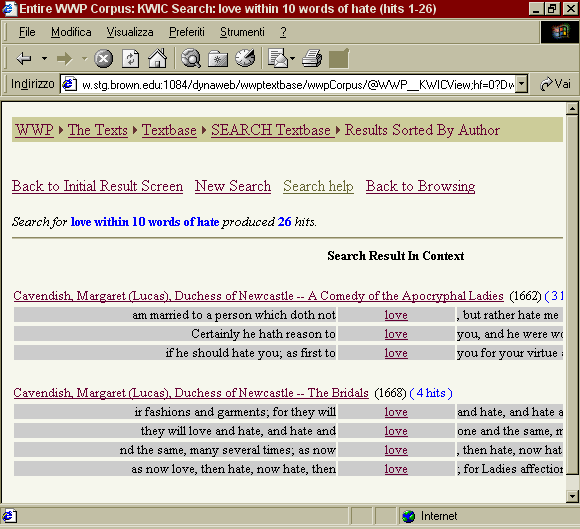
Il sito Web dell'OTA, inoltre, offre una grande quantità di materiali scientifici e di documentazione relativamente agli aspetti tecnici e teorici della digitalizzazione di testi elettronici. Electronic Text CenterL'Electronic Text Center (ETC) ha sede presso la University of Virginia. Si tratta di un centro di ricerca che ha lo scopo di creare archivi di testi elettronici in formato SGML, e di promuovere lo sviluppo e l'applicazione di sistemi di analisi informatizzata dei testi. Tra le varie iniziative lo ETC ha realizzato una importante biblioteca digitale, che ospita molte migliaia di testi, suddivisi in diverse collezioni. La biblioteca digitale dello ETC si basa su una tecnologia molto avanzata. I testi sono tutti memorizzati in formato SGML/TEI, in modo da garantire un alto livello scientifico delle basi di dati. La gestione dell'archivio testuale è affidata a un sistema software molto potente, PAT, un motore di ricerca in grado di interpretare le codifiche SGML. In questo modo è possibile mettere a disposizione degli utenti un sistema di consultazione e di analisi dei testi elettronici che la classica tecnologia Web non sarebbe assolutamente in grado di offrire. Ad esempio, si possono fare ricerche sulla base dati testuale, specificando che la parola cercata deve apparire solo nei titoli di capitolo, o nell'ambito di un discorso diretto. La biblioteca contiene testi in diverse lingue: inglese, francese, tedesco, latino; di recente, in collaborazione con la University of Pittsburgh, sono stati resi disponibili anche testi in giapponese, nell'ambito di un progetto denominato Japanese Text Initiative. Tuttavia, solo alcune di queste collezioni sono liberamente consultabili da una rete esterna al campus universitario della Virginia: tra queste la Modern English Collection, con oltre 1.500 titoli, che contiene anche illustrazioni e immagini di parte dei manoscritti; la Middle English Collection; la Special Collection, dedicata ad autori afro-americani; la raccolta British Poetry 1780-1910. Tutte le risorse offerte dallo ETC, oltre ad una serie di informazioni scientifiche, sono raggiungibili attraverso la home page su World Wide Web, il cui indirizzo è http://etext.lib.virginia.edu. Per finire, il sito offre anche una versione elettronica del manuale della Text Encoding Initiative, sulla quale è possibile fare ricerche on-line. Una risorsa veramente preziosa, se si tiene conto che il testo in questione consta di oltre tremila pagine di specifiche. Women Writers ProjectTra i grandi archivi testuali in area anglosassone possiamo ancora ricordare lo Women Writers Project, sviluppato presso la Brown University, che raccoglie testi della letteratura femminile inglese dal Trecento all'epoca vittoriana, anch'essi interamente in formato TEI. L'indirizzo è http://www.stg.brown.edu/projects/wwp/. Il WWP è dotato di un sistema di archiviazione e accesso ai documenti molto avanzato. Esso si basa su un sistema di archiviazione gestione e ricerca di basi dati documentali in formato SGML, in grado di generare in modo dinamico file HTML [59]. Questa traduzione dinamica è imposta dall'attuale architettura del Web, e in un certo senso determina una perdita di informazione, che però viene sopperita dalla disponibilità di strumenti di ricerca avanzati che agiscono dal lato server, e che dunque possono sfruttare tutti i vantaggi offerti dai documenti strutturati [60]. Grazie a quest'architettura soggiacente, il WWP fornisce un'interfaccia molto avanzata di ricerca sia sui metadati sia sul contenuto dei documenti. L'utente non solamente è in grado di scorrere il testo e di fare ricerche per termini, ma dispone di un vero e proprio ambiente di lavoro virtuale, con strumenti di ricerca contestuale. Ad esempio si possono fare ricerche specificando che il termine cercato debba apparire solo nei titoli di capitolo, o nell'ambito di un discorso diretto, o ancora nel contesto di espressioni in lingue diverse da quella principale del testo.
Una volta effettuata la ricerca, si ottiene un elenco attivo di concordanze in modalità KWIC (Key Word in Context), che permettono a loro volta di accedere ai singoli testi del corpus che contengono occorrenze dei termini ricercati.
Il sistema di biblioteca digitale del WWP mostra anche le possibilità aperte dalle funzionalità ipertestuali dell'ambiente Web. Ogni testo base è inserito in una rete di materiali contestuali di carattere saggistico e didattico. Naturalmente la centralità di un determinato documento è dinamica, e dunque un utente può decidere di adottare un proprio punto di vista circa il 'centro' e la 'periferia' della rete di relazioni. Questo ovviamente richiede una progettazione adeguata dei rapporti ipertestuali che sottostanno alle possibilità di lettura, e soprattutto richiede di avere a disposizione un sistema ipertestuale evoluto che consenta la creazione di collegamenti 'multidirezionali' e di collegamenti categorizzati. Anche in questo ambito le innovazioni introdotte con la famiglia di standard XML potranno aprire delle notevoli prospettive nel prossimo futuro. Altri progetti accademiciMolte altre università o centri di ricerca, per la massima parte collocati negli Stati Uniti, hanno realizzato degli archivi di testi elettronici consultabili su Internet. Una istituzione molto importante nell'ambito disciplinare umanistico è il Center for Electronic Texts in the Humanities (CETH). Fondato e finanziato dalle università di Rutgers e Princeton, il CETH ha lo scopo di coordinare le ricerche e gli investimenti nell'utilizzazione dei testi elettronici per la ricerca letteraria e umanistica in generale. L'indirizzo del sito Web del centro è http://scc01.rutgers.edu/ceth/. Tra i progetti sperimentali del CETH, ci sono una serie di applicazioni della codifica SGML/TEI per la produzione di edizioni critiche di manoscritti e testi letterari. Il centro, inoltre, è sede di importanti iniziative di ricerca, e sponsorizza la più autorevole lista di discussione dedicata alla informatica umanistica, Humanist. Fondata nel maggio del 1987 da un ristretto gruppo di studiosi, Humanist raccoglie oggi centinaia di iscritti, tra cui si annoverano i maggiori esperti del settore. Come tutte le liste di discussione, essa svolge un fondamentale ruolo di servizio, sebbene nei suoi dieci anni di vita sia stata affiancata da innumerevoli altri forum, dedicati ad aspetti disciplinari e tematici specifici. Ma soprattutto, in questi anni, la lista Humanist si è trasformata in un seminario interdisciplinare permanente. Tra i suoi membri infatti si è stabilito uno spirito cooperativo e una comunanza intellettuale che ne fanno una vera e propria comunità scientifica virtuale. Per avere informazioni su questa lista consigliamo ai lettori di consultare la pagina Web ad essa associata, che contiene tutte le indicazioni per l'iscrizione, oltre ad un archivio di tutti i messaggi distribuiti fino ad ora (http://www.princeton.edu/~mccarty/humanist). Molto importante è anche l'Institute for Advanced Technology in the Humanities (IATH), con sede presso la University of Virginia di Charlottesville, un altro tra i maggiori centri di ricerca informatica umanistica nel mondo. Il server Web dello IATH, il cui indirizzo è http://jefferson.village.virginia.edu/, ospita diversi progetti, tra i quali il Rossetti Archive, dedicato al pittore e poeta preraffaellita, nonché una importante rivista culturale pubblicata interamente in formato elettronico sulla quale torneremo in seguito, Postmodern Culture. La Humanities Text Initiative (HTI), con sede presso la University of Michigan, cura una serie di progetti, tra i quali l'American Verse Project, che contiene testi di poeti americani precedenti al 1920. L'indirizzo dello HTI è http://www.hti.umich.edu. Per la letteratura francese è invece di grande importanza il progetto ARTFL (Project for American and French Research on the Treasury of the French Language), supportato dal Centre National de la Recherche Scientifique (CNRS) e dalla University of Chicago. L'archivio permette la consultazione on-line di un database contenente oltre duemila testi sia letterari sia non letterari, sui quali è possibile effettuare ricerche e spogli lessicali (non è invece possibile prelevare i file contenenti i testi), ma l'accesso ai servizi più avanzati è purtroppo riservato ad istituzioni che abbiano effettuato una esplicita iscrizione. L'indirizzo Web del progetto ARTFL è http://humanities.uchicago.edu/ARTFL/ARTFL.html. Da ricordare anche il prestigioso Dartmouth Dante Project, uno tra i più antichi progetti di banche dati testuali. Come si evince dal nome, si tratta di una banca dati dedicata specificamente agli studi danteschi. Il database contiene allo stato attuale, insieme all'opera omnia del poeta, i testi di tutti i commenti danteschi redatti dal Trecento alla metà del nostro secolo: una fonte di informazione preziosissima. La banca dati è raggiungibile via telnet, all'indirizzo library.dartmouth.edu: per consultare il Dante Project bisogna digitare nella schermata iniziale 'CONNECT DANTE'. Recentemente è stata sviluppata anche un'interfaccia Web, che consente di fare le medesime ricerche con minore difficoltà (anche se non va dimenticato che stiamo parlando di una risorsa estremamente specialistica), raggiungibile da un elenco delle banche dati disponibili presso la biblioteca di Dartmouth all'indirizzo http://www.dartmouth.edu/%7Elibrary/infosys/dciswww/prod/Literature.html. Un altro prestigioso progetto in area umanistica è il Perseus Project (http://www.perseus.tufts.edu). Il progetto, avviato nel 1985, si proponeva di realizzare un'edizione elettronica della letteratura greca. Da allora sono state realizzate due edizioni su CD ROM, divenute un insostituibile strumento di lavoro nell'ambito degli studi classici, contenenti i testi di quasi tutta la letteratura greca in lingua originale e in traduzione, nonché un archivio di immagini su tutti gli aspetti della cultura dell'antica Grecia. Nel 1995 è stata creata anche una versione su Web del progetto, il Perseus Digital Library. Il sito consente di accedere gratuitamente a tutti i materiali testuali del CD, a una collezione di testi della letteratura latina in latino e in traduzione inglese, alle opere complete del tragediografo rinascimentale inglese Christopher Marlowe, e a vari materiali relativi a Shakespeare. L'individuazione e la consultazione dei singoli testi possono avvenire mediante un motore di ricerca, o un elenco degli autori contenuti in ciascuna collezione, da cui si passa direttamente alla visualizzazione on-line. I testi greci possono essere visualizzati sia nella traslitterazione in alfabeto latino, sia direttamente in alfabeto greco (posto che si abbia un font adeguato: comunque sul sito sono disponibili tutte le istruzioni del caso) sia in traduzione inglese (quest'ultima è disponibile anche per i testi latini). Per i testi greci è anche possibile avere informazioni morfosintattiche e lessicografiche per ogni parola. Insomma, un vero e proprio strumento scientifico, oltre che un prezioso supporto per la didattica. Per finire, segnaliamo alcune iniziative italiane. Al momento due sono i progetti a carattere nazionale. Il progetto CIBIT (Centro Interuniversitario Biblioteca Italiana Telematica, http://www.humnet.unipi.it/cibit), che raccoglie undici università, sta realizzando una biblioteca digitale basata sul software di analisi testuale DBT, sviluppato presso l'Istituto di linguistica computazionale di Pisa. La collezione testuale del CIBIT si colloca nell'ambito della tradizione letteraria italiana, ma contiene anche testi di carattere storico, giuridico, politico, filosofico e scientifico. Per il momento è presente in rete con una versione sperimentale che utilizza un applet Java come front end di interrogazione verso il database testuale remoto. Il sistema permette di effettuare ricerche e concordanze dinamiche, ma è limitato dal formato di codifica dei documenti, che si basa essenzialmente sulla semplice codifica dei caratteri e di alcuni semplici riferimenti testuali. Anche la scelta di basare il modulo di interrogazione su un applet Java di una certa consistenza suscita alcune perplessità, poiché richiede la disponibilità di linee piuttosto veloci per evitare lunghe attese in fase di accesso. Il progetto TIL (Testi Italiani in Linea, http://til.let.uniroma1.it), invece, raccoglie sei università, coordinate dal Dipartimento di studi linguistici e letterari di Roma 'La Sapienza'. Anche in questo caso si tratta di un progetto che è ancora in fase sperimentale, incentrato sulla tradizione letteraria italiana. Dal punto di vista tecnico la biblioteca digitale del TIL si basa sulla medesima tecnologia adottata dal Women Writers Project. I testi, codificati in SGML/TEI, sono interrogabili, mediante una semplice interfaccia Web, sfruttando a pieno le informazioni strutturali veicolate dalla codifica. Ogni testo presente nella biblioteca digitale, inoltre, è corredato da un serie di materiali introduttivi e di contesto, che servono a fornire agli utenti nozioni di base relative alle opere archiviate. Accanto alla collezione principale, che sostanzialmente costituisce un vero e proprio canone della letteratura italiana, sono presenti alcune collezioni speciali dedicate ad autori, periodi storici o generi letterari, in cui i documenti sono stati sottoposti ad un processo di codifica SGML più avanzato, e che di conseguenza possono essere sottoposti a forme di interrogazione di livello specialistico. Su una scala minore, infine, ricordiamo le sperimentazioni condotte presso il Centro Ricerche Informatica e Letteratura (CRILet, http://crilet.let.uniroma1.it). La prima riguarda la pubblicazione su Web di edizioni scientifiche di opere della letteratura italiana codificate in formato SGML/TEI, che possono essere visualizzate mediante il browser Panorama. La seconda invece consiste nella creazione di una banca dati testuali on-line basata sul sistema di interrogazione Tactweb (la versione on-line del fortunato software di analisi testuale TACT), che consente di effettuare raffinate ricerche sui testi. I progetti non istituzionaliCome abbiamo visto, il tema delle biblioteche digitali è al centro dell'interesse della comunità scientifica internazionale e attira grandi progetti di ricerca e notevoli finanziamenti. Ma in questo settore, come spesso è avvenuto su Internet, le prime iniziative sono nate al di fuori di luoghi istituzionali, per opera del volontariato telematico. Novelli copisti, che, nell'era digitale, hanno ripercorso le orme dei monaci medievali, i quali salvarono il patrimonio culturale dell'antichità, e dei primi grandi stampatori che, a cavallo tra Quattro e Cinquecento, diedero inizio all'era della stampa. E non è un caso che alcuni di questi progetti abbiano scelto di onorare questa ascendenza, intitolandosi con i nomi di quei lontani maestri: Johannes Gutenberg, Aldo Manuzio. I progetti di questo tipo sono numerosi, con vari livelli di organizzazione, partecipazione, dimensione e attenzione alla qualità scientifica dei testi pubblicati. Ne esamineremo due in particolare: il Project Gutenberg, il capostipite delle biblioteche digitali, e il Progetto Manuzio, dedicato alla lingua italiana. Progetto GutenbergIl Progetto Gutenberg è senza dubbio una delle più note e vaste collezioni di testi elettronici presenti su Internet. Non solo: è anche stata la prima. Le sue origini, infatti, risalgono al lontano 1971, quando l'allora giovanissimo Michael Hart ebbe la possibilità di accedere al mainframe Xerox Sigma V della University of Illinois. Hart decise che tanta potenza poteva essere veramente utile solo se fosse stata usata per diffondere il patrimonio culturale dell'umanità al maggior numero di persone possibile. E digitò manualmente al suo terminale il testo della Dichiarazione di indipendenza degli Stati Uniti. Nel giro di pochi anni il progetto Gutenberg, nome scelto da Hart in omaggio all'inventore della stampa, le cui orme stava ripercorrendo, attirò decine e poi centinaia di volontari, che iniziarono a contribuire all'obiettivo individuato dal fondatore: raggiungere i diecimila titoli entro il 2001. Per lungo tempo l'iniziativa ha anche goduto dell'esiguo supporto finanziario e logistico di alcune università, supporto che è venuto a mancare nel dicembre 1996. Nonostante il periodo di difficoltà, Michael Hart non si è perso d'animo; anzi è riuscito a potenziare ulteriormente la sua incredibile creatura. Infatti, accanto al patrimonio testuale in lingua inglese, che costituisce il fondo originario e tuttora portante della biblioteca, recentemente sono state aggiunte trascrizioni da opere in molte altre lingue, tra cui il francese, lo spagnolo e l'italiano. Nel momento in cui scriviamo l'archivio contiene più di 2 mila testi - prevalentemente testi della letteratura inglese e americana, ma anche testi saggistici traduzioni di opere non inglesi e testi in altre lingue. Circa settecento volontari in tutto il mondo collaborano all'incremento con un tasso di quaranta nuovi titoli al mese. I testi sono programmaticamente in formato ASCII a sette bit (il cosiddetto Plain Vanilla ASCII). Michael Hart, infatti, ha sempre affermato di volere realizzare una banca dati che potesse essere utilizzata da chiunque, su qualsiasi sistema operativo, e in qualsiasi epoca: tale universalità è a suo avviso garantita solo da questo formato. Lo stesso Hart ha più volte declinato gli inviti a realizzare edizioni scientifiche dei testi. Infatti lo spirito del progetto Gutenberg è di rivolgersi al novantanove per cento degli utenti fornendo loro in maniera del tutto gratuita testi affidabili al novantanove per cento. Come ha più volte affermato, fare un passo ulteriore richiederebbe dei costi che non sono alla portata di un progetto interamente basato sul volontariato, e sarebbe al di fuori degli obiettivi di questa iniziativa. Il sito di riferimento del progetto Gutenberg su Web è all'indirizzo http://www.gutenberg.net, e contiene il catalogo completo della biblioteca, da cui è possibile ricercare i testi per autore, titolo, soggetto e classificazione LC. Una volta individuati i titoli, è possibile scaricare direttamente i file (compressi nel classico formato zip). Ma il progetto Gutenberg per la sua notorietà è replicato su moltissimi server FTP, e viene anche distribuito su CDROM dalla Walnut Creek. Al progetto Gutenberg sono anche dedicati una mail list e un newsgroup, denominato bit.listserv.gutenberg, tramite i quali si possono avere informazioni sui titoli inseriti nella biblioteca, si può essere aggiornati sulle nuove edizioni, e si possono seguire i dibattiti che intercorrono tra i suoi moltissimi collaboratori. Progetto ManuzioIl Progetto Manuzio è la più importante collezione di testi in lingua italiana nata nell'ambito del volontariato telematico. Questa iniziativa, in analogia al progetto Gutenberg, prende il suo nome dal noto stampatore Aldo Manuzio, considerato uno dei massimi tipografi del Rinascimento. Il progetto Manuzio è gestito da una associazione culturale denominata Liber Liber (della quale fanno parte tutti e quattro gli autori del manuale che state leggendo), che coordina il lavoro offerto - a titolo del tutto gratuito e volontario - da numerose persone. Grazie a questo sostegno il progetto ha potuto acquisire in poco tempo numerosi testi, fra cui si trovano grandi classici quali la Divina Commedia, i Promessi sposi, i Malavoglia, ma anche opere rare e introvabili da parte di lettori 'non specialisti'. L'archivio del progetto è costituito da testi in formato ISO Latin 1. Alcuni titoli sono stati codificati anche in formato HTML - e dunque possono essere consultati direttamente on-line tramite un browser Web - e in formato RTF. Allo stato attuale l'archivio comprende circa quattrocento titoli, tutti disponibili gratuitamente. Le pagine Web dell'associazione Liber Liber, all'indirizzo http://www.liberliber.it, contengono il catalogo completo dei testi disponibili, insieme ad informazioni sull'iniziativa. Il catalogo è organizzato per autori, e offre per ogni titolo una breve scheda informativa nella quale, oltre ai dati bibliografici essenziali e una breve nota di commento, sono indicati l'autore del riversamento, i formati di file disponibili e il livello di affidabilità del testo. Il progetto, infatti, ha l'obiettivo di fornire testi completi e filologicamente corretti, compatibilmente con la natura volontaria del lavoro di edizione. Il progetto Manuzio è nato come biblioteca di classici della letteratura italiana. In questo ambito si colloca il suo fondo principale, che comprende opere di Dante, Boccaccio, Ariosto, Leopardi, Manzoni, Verga. Ma con il passare degli anni il progetto si è sviluppato in direzione di un modello di biblioteca generalista; sono infatti state accolte anche traduzioni di testi non italiani, una serie di opere di saggistica, oltre ai Verbali della Commissione parlamentare antimafia. La biblioteca ospita anche un'importante rivista scientifica, Studi Storici, edita dall'Istituto Gramsci. Alcuni titoli della biblioteca, ancora coperti da diritti d'autore, sono stati donati direttamente da case editrici o da privati che ne possedevano la proprietà intellettuale. Questo esempio di collaborazione tra editoria elettronica ed editoria tradizionale dimostra come i supporti elettronici non debbano essere necessariamente pensati in conflitto con i libri a stampa. Proprio in questi casi, anzi, la libera disponibilità e circolazione dei testi elettronici si trasforma in uno strumento di promozione per il libro stampato e, in ultima analisi, in un potente veicolo di diffusione culturale. Anche per questo motivo abbiamo scelto dal canto nostro di inserire Internet 2000 (come è avvenuto per le precedenti edizioni di questo manuale) fra i titoli del progetto. Altri archivi testualiSulla scia del capostipite Gutenberg, sono nati una serie di progetti simili, dedicati ad altre letterature nazionali. L'omonimo progetto Gutenberg per la letteratura tedesca, ad esempio, si trova all'indirizzo http://gutenberg.aol.de/. Il progetto Runeberg per le letterature scandinave è uno dei maggiori archivi europei di testi elettronici. Nato come progetto volontario, ora è gestito congiuntamente da Lysator (un centro di ricerca informatico molto importante) e dalla Università di Linköping. Contiene infatti oltre duecento tra classici letterari e testi folclorici provenienti da Svezia, Norvegia e Danimarca. I testi sono consultabili on-line su World Wide Web all'indirizzo http://www.lysator.liu.se/runeberg/. Il progetto ABU (Association des Bibliophiles Universels, nome anche dell'associazione che lo cura, tratto dal romanzo di Umberto Eco Il pendolo di Foucault) sta realizzando un archivio di testi della letteratura francese. Fino ad ora possiede un archivio di 200 classici tra cui opere di Molière, Corneille, Voltaire, Stendhal, Zola, nonché una trascrizione della Chanson de Roland, nel manoscritto di Oxford. ABU, come il progetto Manuzio, sta accogliendo contributi originali donati da autori viventi, e alcune riviste. Il progetto ABU ha una pagina Web all'indirizzo http://cedric.cnam.fr/ABU/, dalla quale è possibile consultare ed effettuare ricerche on-line sui testi archiviati; la stessa pagina contiene anche un elenco di altre risorse su Internet dedicate alla cultura e alla letteratura francese. Ricordiamo infine anche il Progetto Libellus. Come il nome lascia intendere, si tratta di un archivio contenente trascrizioni elettroniche dei classici latini, affiancati da alcuni commenti. Recentemente è stata aggiunta anche una sezione per i classici greci. L'indirizzo dell'archivio è http://osman.classics.washington.edu/libellus/libellus.html, e contiene testi in formato HTML e in formato TEX, un linguaggio di codifica molto usato per la preparazione di stampe professionali. Note [54] V. Bush, As we May Think, 1945, traduzione italiana in T. Nelson, Literary Machine 90.1, 1992, par.1/38. [55] T. Nelson, op. cit. [56] Accanto o in alternativa al termine 'biblioteca digitale' si incontra spesso quello di 'biblioteca virtuale'. L'aggettivo 'virtuale' nella cultura di rete viene usato sia come sinonimo di 'immateriale', sia come termine tecnico in riferimento all'applicazione di tecnologie di realtà virtuale. In entrambi i casi, la sua applicazione al dominio degli archivi testuali on-line si carica di sensi impropri. Per tale ragione preferiamo non adottarlo. Una distinzione tassonomica tra 'biblioteca digitale' e 'biblioteca virtuale' che ci sembra possa essere accolta è quella proposta da Carla Basili (Le biblioteche in rete, Editrice bibliografica, Milano 1999) che, nell'ottica client-server che caratterizza le applicazioni di rete, pone la prima sul lato server e la seconda sul lato client. [57] Ritorneremo con maggiore attenzione sia sui sistemi di codifica dei caratteri sia sui linguaggi di markup e su SGML nel capitolo 'Come funziona World Wide Web'. [58] XML costituisce il perno di una profonda innovazione dell'architettura Web su cui torneremo nel capitolo 'Come funziona World Wide Web'. Il World Wide Web Consortium è l'organizzazione indipendente deputata allo sviluppo delle tecnologie e dell'architettura del Web. Tutta la documentazione sugli standard elaborati in tale sede che citeremo è disponibile liberamente presso il sito del W3C, all'indirizzo http://www.w3.org. [59] Si tratta di Dynatext/Dynaweb, realizzato dalla Inso (http://www.inso.com) con il contributo di alcuni ricercatori dello Scholarly Technology Group della Brown University. [60] Da questo punto di vista l'introduzione di XML, su cui torneremo nella sezione dedicata alle 'Tecnologie', potrebbe rappresentare un decisivo passo in avanti, permettendo la distribuzione di documenti variamente codificati anche dal lato client. |

![]()